
MLOps Nedir? Github Actions ile CML
Published:

MLOps Nedir?
MLOps en basit haliyle DevOps ilkelerinin ML için uygunlanması olarak tanımlanabilir. Veri bilimi ekibi ile operasyon ekibinin canlıdaki ML ürünlerine ait döngüyü sağladığı süreç olarak da tanımlamak mümkün. Güvenlik (uygulama ve veri), yasal düzenlemeler (KVKK & GDPR) ve işe (business) ait kısıtlarla birlikte otomasyonun ve ürün kalitesinin artırılması amaçlanır. Bu amaçla da CI/CD, orkestrasyon, yönetim, deployment, monitoring gibi yazılım geliştirme döngüsünde (software development cycle) bulunan süreçlerden yararlanılır.

Github Actions
Actions, Github’ın yaklaşık bir yıl önce kullanıma açtığı bir CI/CD aracı. Build alabileceğiniz, test edebileceğiniz, belirtilmiş olan aşamaları sağlaması durumunda deploy edebileceğiniz ve buna benzer işlemleri pek çok dil, framework için farklı senaryolarla birlikte kullanabileceğiniz bir araç. Bir repo oluşturduğunuz anda otomatik olarak geliyor ve projenize uygun olabilecek kurulumları kendi öneriyor. Bunun yanı sıra Actions için yazılmış ve paylaşılmış bir hayli workflow (akış) bulabiliyorsunuz. Bir yaml dosyası oluşturarak kendi senaryonuzu belirliyor (örneğin her commit sonrası ya da Release etiketine sahip commit’ler için gibi) ve akışınız şart sağlandığında çalışıyor. Actions altında farklı yaml dosyalarını, ve bunlara ait çıktıları görebiliyorsunuz. Ayrıca isterseniz kendi sunucunuzu Github Actions’a ekleyerek Actions’ı bir otomasyon aracı (Jenkins) gibi kullanabilirsiniz.

About Github Actions
- Workflow yazarken kullanabileceğiniz syntax’a buradan erişebilirsiniz.
CML
CML, DVC‘yi (Data Version Control) geliştiren ekip tarafından geliştirilen, adını Countious Machine Learning kelimelerinin ilk harflerinden alan ML projeleri için kullanılan açık kaynak bir CI/CD aracı. CML ile Markdown biçiminde rapor alabilir ya da DL modelinize ait Tensorboard çıktısını görebilirsiniz. Şu an her ne kadar yeni sayılsa da önünün bir hayli açık olduğu söylenebilir. Zira bu alandaki ihtiyaç da aynı şekilde artmakta.
CML’i geliştirirken temel aldıkları durumlar ise şu şekilde;
- DVC’deki gibi bir GitFlow oluşturulması. Bu şekilde model kim tarafından çalıştırıldı, veride değişiklik oldu mu gibi durumlar takip edilebilir.
- Model çalıştıktan sonra otomatik olarak çıktının raporlanması (otomasyon).
- Son olarak ise herhangi bir ekstra uygulamaya ihtiyaç duymadan sadece Github veya Gitlab ve bulut sağlayıcılar ile çalışması.
Dökümanında paylaşılan örnek yaml dosyasını aşağıda görebilirsiniz.
name: train-my-model # workflow adı
on: [push] # hangi durumda tetiklenecek?
jobs: # tetiklendikten sonra ne yapacak?
run:
runs-on: [ubuntu-latest] # hangi platformda çalışacak?
container: docker://dvcorg/cml-py3:latest # Docker imajı olarak cml-py3 kullanıyor. Detay > https://hub.docker.com/r/dvcorg/cml-py3
steps:
- uses: actions/checkout@v2 # repo'ya erişmek için kullanılan proje -> github.com/actions/checkout
- name: cml_run
env:
repo_token: $
run: | # docker imajı içerisinde çalışacak komutlar
pip3 install -r requirements.txt
python train.py
cat metrics.txt >> report.md
cml-publish confusion_matrix.png --md >> report.md
cml-send-comment report.md
Bu örnek akışın çıktısı ise bu şekilde;

Kaynak Repo
Ben de bu örnek yaml‘ı temel alarak benzeri bir workflow oluşturmak istedim. Kaggle’da bulunan IBM HR Analytics Employee Attrition & Performance veri seti kullanılarak bir model kuruldu. Bu örnekteki gibi değişken önemini (feature importance) alabileceğimiz bir algoritma olan Random Forest’ı tercih edildi. Fakat buna ek olarak biraz daha açıklanabilirliği arttırmak adına shap kullanıldı. train_model.py ve train_model_shap.py olacak şekilde iki tane Python script’i ve buna bağlı olarak da iki tane requirements.txt hazırlandı.
Random Forest Baseline
Bu aşamadan sonrası pandas ve scikit-learn aslında. Hem işe yarayacağını düşündüğüm hem de modele gürültü (noise) ekleyebileceğini düşündüğüm değişkenler oluşturdum. Amaç sonrasında değişken seçimi yapıp bunlar arasından etkili olanları seçerek hem model başarımını arttırmak hem de açıklanabilirlik ile modele etkisini görebilmek.
train_model.py için İlk olarak script içerisinde kullanılacak parametreleri eklendi. Bunlardan feature_ext yeni değişken üretilip üretilmeyeceğine karşılık gelirken top_n ise workflow sonucunda değişken önemi için kaç değişkenin alınacağına karşılık geliyor. Yapılan işlemlerin tekrar edilebilir olması için de seed 2020 olarak tanımlanıyor.
feature_ext = False
top_n = 15
seed = 2020
Sonrasında ise verinin okunması, tek değeri olan değişkenlerin çıkarılması ve if koşulunu sağlaması durumunda yeni değişkenlerin oluşturulduğu kısım bulunmakta.
data = pd.read_csv("HR-Employee-Attrition.csv")
data["Attrition"] = data["Attrition"].map({'Yes':1, 'No':0})
constant_cols = data.nunique()[data.nunique() == 1].keys().tolist()
data.drop(constant_cols, axis=1, inplace=True)
if feature_ext: # Oluşturulan Değişkenler
print("[INFO] Feature Extraction")
data["RoleChangeYear"] = data["YearsAtCompany"] - data["YearsInCurrentRole"]
data["PromChangeYear"] = data["YearsAtCompany"] - data["YearsSinceLastPromotion"]
data["ManagerChangeYear"] = data["YearsAtCompany"] - data["YearsWithCurrManager"]
data["JobChangeYear"] = data["TotalWorkingYears"] - data["YearsAtCompany"]
data["AvgCompYear"] = data["TotalWorkingYears"] / data["NumCompaniesWorked"]
data["DayMonthRate"] = data["DailyRate"] / data["MonthlyRate"]
data["StartAge"] = data["Age"] - data["TotalWorkingYears"]
data["WorkLifePercent"] = data["StartAge"] / data["Age"]
data["is_firstJob"] = np.where(data["NumCompaniesWorked"] == 0, 1, 0).astype(str)
data["is_TrainedLY"] = np.where(data["TrainingTimesLastYear"] != 0, 1, 0).astype(str)
data["AnnualSalary"] = data["MonthlyIncome"] * 12
data["is_promoted"] = np.where(((data["YearsInCurrentRole"] - data["YearsSinceLastPromotion"]) != 0), 1, 0)
data["MonthlyIncomeDistMean"] = data["MonthlyIncome"] / data.groupby("DistanceFromHome")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeJobLvlMean"] = data["MonthlyIncome"] / data.groupby("JobLevel")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeEduMean"] = data["MonthlyIncome"] / data.groupby("Education")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeRoleMean"] = data["MonthlyIncome"] / data.groupby("JobRole")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeStockOptMean"] = data["MonthlyIncome"] / data.groupby("StockOptionLevel")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeOTMean"] = data["MonthlyIncome"] / data.groupby("OverTime")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeDepMean"] = data["MonthlyIncome"] / data.groupby("Department")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeEduFieldMean"] = data["MonthlyIncome"] / data.groupby("EducationField")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeAgeMean"] = data["MonthlyIncome"] / data.groupby("Age")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeGenMean"] = data["MonthlyIncome"] / data.groupby("Gender")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeisFJMean"] = data["MonthlyIncome"] / data.groupby("is_firstJob")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeTrvlMean"] = data["MonthlyIncome"] / data.groupby("BusinessTravel")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeMaritMean"] = data["MonthlyIncome"] / data.groupby("MaritalStatus")["MonthlyIncome"].transform("mean")
data["MonthlyIncomeWLB"] = data["MonthlyIncome"] / data.groupby("WorkLifeBalance")["MonthlyIncome"].transform("mean")
data.loc[data.AvgCompYear.isna(), "AvgCompYear"] = 0
Değişkenler oluşturulduktan sonra ise sayısal ve kategorik değişken isimlerine ait listeler oluşturuyorum. Buna ek olarak K-Means kullanacağımız için 10’dan fazla tekil değer içeren değişkenleri -1 ile 1 arasında ölçeklendiriyoruz. Devamında ise kategorik değişkenler için Label Encoding kullanarak onları da sayısal hale getiriyoruz. Bu aşamadan sonra veri seti K-Means için hazır hale geliyor. Detaylarını bir başka yazıda paylaşmayı düşündüğüm segmentasyon aşamasında ise kategorik değişkenleri kullanarak 2 küme, sayısal değişkenleri kullanarak da 3 küme olan iki K-Means modeli kuruluyor ve küme indisleri değişken olarak ekleniyor.
target = ["Attrition"]
num_cols = [
num for num in data.select_dtypes(exclude=["O"]).columns.tolist()
if num not in target + ["EmployeeNumber"] + constant_cols
]
cat_cols = [
cat for cat in data.select_dtypes("O").columns.tolist()
if cat not in constant_cols
]
scale_cols = [
c for c in data.nunique()[data.nunique() > 10].keys().tolist()
if c not in ["EmployeeNumber"] + target]
df = data.copy()
df = df.replace([np.inf, -np.inf], np.nan)
for scl in scale_cols:
df[scl] = pd.DataFrame(StandardScaler().fit_transform(
df[scl].fillna(-1).values.reshape(-1, 1)),
columns=[scl])
le = LabelEncoder()
for cat in cat_cols:
df[cat] = le.fit_transform(df[cat])
ncls_cat = 2
model_cat = KMeans(n_clusters=ncls_cat, random_state=seed)
model_cat.fit(df[cat_cols])
ncls_num = 3
model_num = KMeans(n_clusters=ncls_num, random_state=seed)
model_num.fit(df[num_cols])
df["clsNum"] = model_num.predict(df[num_cols])
df["clsCat"] = model_cat.predict(df[cat_cols])
Son kod bloğunda ise veriyi train ve test olacak şekilde ayırıyoruz. Sonrasında ise Random Forest ile modelimizi oluşturuyor ve test’e ait tahminleri elde ediyoruz. Bunun yanı sıra train ve test için skorlarımızı alıyoruz. Modele ait değişken önemini de DataFrame haline getirip seaborn kullanarak en yüksek öneme sahip ilk 15 değişkenin değişken önemini çubuk grafik (bar plot) olarak kaydediyoruz. Son olarak ise daha önce hesapladığımız skorları rf_metrics.txt adında bir metin belgesine kaydediyoruz.
target = "Attrition"
train_cols = [c for c in df.columns
if c not in [target]]
x_train, x_test, y_train, y_test = train_test_split(df[train_cols],
df[target],
test_size=0.2,
random_state=seed,
stratify=df[target])
(x_train.shape, y_train.shape), (x_test.shape, y_test.shape)
model = RandomForestClassifier(n_estimators=150,
class_weight="balanced",
min_samples_leaf=10,
min_samples_split=5,
random_state=seed)
model.fit(x_train, y_train)
model_preds = model.predict_proba(x_test)[:, 1]
f1_train, acc_train, rec_train, prec_train = scorer(y_train,
model.predict(x_train),
is_return=True)
f1_pred, acc_pred, rec_pred, prec_pred = scorer(y_test,
model_preds,
is_return=True)
feature_df = pd.DataFrame(list(zip(train_cols, model.feature_importances_)),
columns=["feature", "importance"])
feature_df = feature_df.sort_values(
by='importance',
ascending=False,
)
axis_fs = 14
title_fs = 18
sns.set(style="whitegrid")
ax = sns.barplot(x="importance", y="feature", data=feature_df.head(top_n))
ax.set_xlabel('Importance', fontsize=axis_fs)
ax.set_ylabel('Feature', fontsize=axis_fs)
ax.set_title('Random Forest Feature Importance',
fontsize=title_fs)
plt.tight_layout()
plt.savefig("rf_feature_importance.png", dpi=250)
plt.close()
with open("rf_metrics.txt", 'w') as outfile:
outfile.write(
"Train Metrics\nF1: %0.5f \nAccuracy: %0.5f \nRecall: %0.5f \nPrecision: %0.5f \n"
% (f1_train, acc_train, rec_train, prec_train))
outfile.write(
"Test Metrics\nF1: %0.5f \nAccuracy: %0.5f \nRecall: %0.5f \nPrecision: %0.5f \n"
% (f1_pred, acc_pred, rec_pred, prec_pred))
Bu workflow’un çalışması sonucunda elde ettiğimiz çıktıyı github-actions bot ilgili commit’in altına yorum olarak ekliyor;
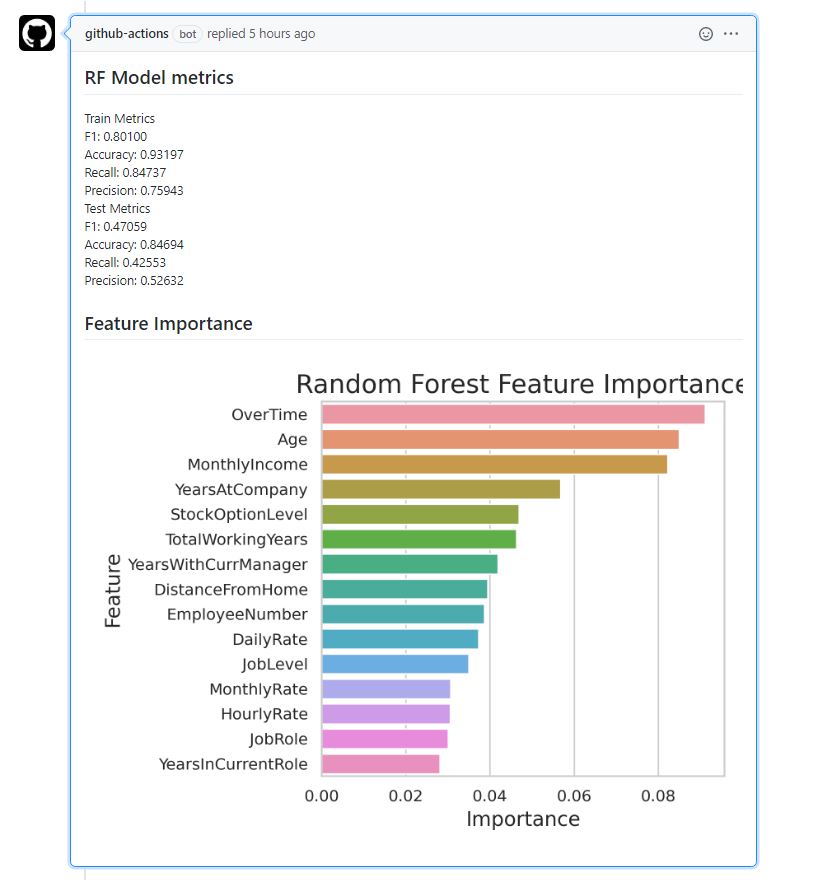
Random Forest V2
Bu modelde diğerinden farklı olarak LOFO kullanarak seçilen değişkenler ile model kuruyoruz ve her bir değişkene ait bağımlılık grafikleri (dependence plot) ile tüm değişkenlerin etkisini görebileceğimiz summary_plot‘u kullanıyoruz.
Ahmet Erdem tarafından geliştirilen LOFO (Leave One Feature Out) seçilen model, validasyon şeması (CV) ve metrik için iteratif bir şekilde her iterasyonda bir değişken çıkararak değişkenlerin modele olan etkisini hesaplar. Buna göre de her bir değişkene ait ortalama değişken önemini ve standart sapmasını döndürür. Örnek notebook’a buradan erişebilirsiniz.
feature_ext = True
use_shap = True
if feature_ext:
selected_cols = True
top_n = 15
seed = 2020
Değişken seçimi yaptığımız için yeni değişkenleri elle veriyorum fakat yine de tüm değişkenlere ait shap değerlerini görmek istersek diye bunu da True/False olacak şekilde veriyoruz.
if selected_cols: # LOFO ile seçilen değişkenler, henüz elle belirleniyor :/
train_cols = [
'OverTime', 'DistanceFromHome', 'JobSatisfaction', 'JobRole',
'EnvironmentSatisfaction', 'Department', 'BusinessTravel',
'EducationField', 'Education', 'MaritalStatus', 'JobLevel',
'NumCompaniesWorked', 'MonthlyIncomeTrvlMean', 'ManagerChangeYear',
'JobInvolvement', 'WorkLifeBalance', 'MonthlyIncome', 'StockOptionLevel',
'DailyRate', 'MonthlyIncomeMaritMean', 'MonthlyIncomeRoleMean','MonthlyIncomeWLB',
'WorkLifePercent', 'JobChangeYear', 'Gender', 'clsCat','clsNum']
else:
train_cols = [c for c in df.columns
if c not in [target]]
Bu aşamadan sonra yine baseline modelde olduğu şekilde aynı parametreler ile modeli kuruyoruz. Son olarak shap aşamasında aşağıdaki kod bloğunu ekliyoruz. (shap grafiklerine ait detayları burada bulabilirsiniz).
if use_shap:
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x_train)
shap.force_plot(explainer.expected_value[1], shap_values[1][0,:], x_train.iloc[0,:], show=False, matplotlib=True).savefig('single_pred.png')
plt.close()
shap.summary_plot(shap_values, x_train, feature_names=train_cols, show=False)
plt.savefig('summary_plot_rf.png', format='png', dpi=200)
plt.close()
for name in train_cols:
shap.dependence_plot(name, shap_values[1], x_train, show=False)
plt.savefig('dependence_%s.png'%name, format='png', dpi=200)
plt.close()
Actions için hazırladığımız yeni yaml‘da ise aşağıdaki eklemeyi yapıyoruz.
echo "## Feature Importance & Shap Plots" >> model_report.md
for i in *.png; do
[ -f "$i" ] || break
cml-publish $i --md >> model_report.md
done
cml-send-comment model_report.md
Python scriptinde png olarak kaydettiğimiz tüm görselleri tek tek eklemek yerine bash script kullanarak for döngüsü ile *.png uzantılı tüm dosyaları almasını söylüyoruz. Böylece hem tek tek yazmamıza hem de değişken seçimi için eklenebilecek bir aşama için değişiklik yapmamıza gerek kalmıyor.
Bu yaml sonucunda github-actions bot’un commit altına eklediği yorum; 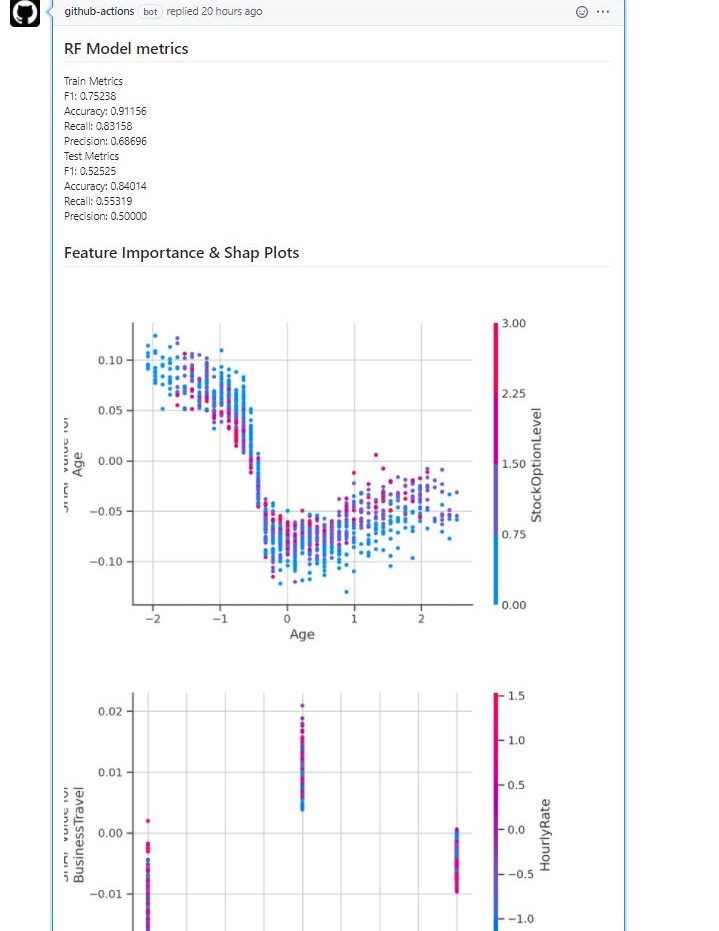
Toplamda 30 civarında grafik oluşturulduğu için ekran görüntüsüne sığmıyor tabii ki. İsimlendirme gereği ilk olarak alfabetik olarak bağımlılık grafikleri geliyor sonrasında ise modele ait değişken önemi. Devamında da eğitim setinin ilk satırına ait force_plot grafiği ve son olarak da tüm değişkenlerin genel etkisini gösteren summary_plot geliyor. Github bununla da yetinmiyor. Hem bildirim olarak hem de mail olarak sonucu gönderiyor. 

Son olarak farkettiğim bir farklılık ise uygulamanın çalıştığı platformdaki farklılık. Kendi bilgisayarımda WSL üzerinden ve Windows 10 üzerinden çalıştırdığım aynı script’te farklı sonuçlar aldım. Bunun nedeni ise (tahminimce) Linux ve Windows’taki seed mekanizmasının farklılığı. Bu nedenle iki farklı skor elde edilmiş olmalı. Dolayısıyla Actions üzerinde alacağınız sonuçta da farklılık görmeniz mümkün.

- Projenin Github repo’su.
- Workflow’ların çıktılarını takip etmek için Actions
- Model raporlarının yazıldığı commit geçmişi
Güncelleme: Repo yapısını değiştirerek R ile de benzeri bir örnek ekledim. (16/10/2020)



