
MLOps: Streamlit ve Heroku ile Canlıya Çıkmak
Published:
Uygulamaya buradan ulaşabilirsiniz.
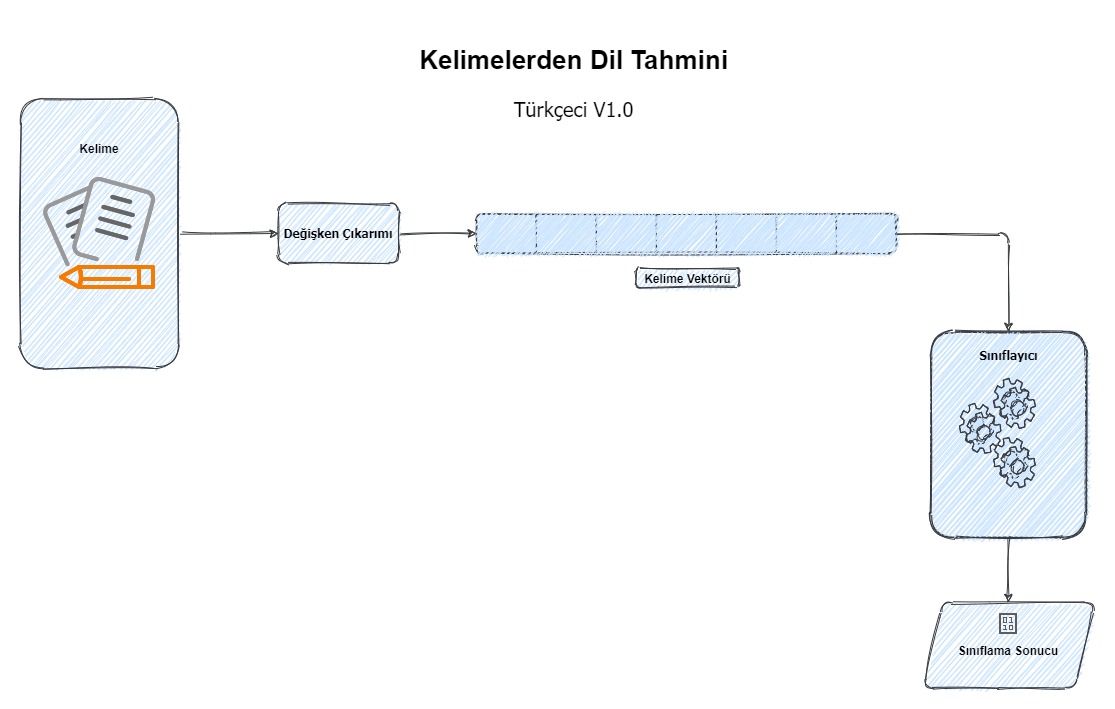
Bu çalışmada Stacking ile Kelimelerden Dil Tahmini çalışmasını baz alarak benzeri bir veri seti ile bu çalışmadan daha fazla kelime kullanarak doğrusal ve doğrusal olmayan modeller kullanılarak Türkçe ve İngilizce kelimeler için sınıflama yapıldı. Bu sefer amaç çok daha iyi sonuç veren modeller elde etmek yerine modelleri canlıya almaktı. Nitekim öyle de oldu çünkü model başarımları canlıda çok da iyi görünmüyor.
Problem, veri önişleme, modelleme aşamaları daha önceki çalışma ile (%99) benzer. Bu çalışmada farklı olarak kelimelerin dağılımına bakıp kısmen normal dağılıma yaklaştırıldı, böylece az 3 harf ve en fazla 16 harfli kelimeler için filtreleme yapıldı. Kelimelerin vektörhaline getirilmesi amacıyla bu sefer TF-IDF kullanılmadı sadece CountVectorizer ile kelimeler vektör haline getirildi. Yine aynı şekilde sesli, sesiz ve toplam harf sayısı değişkenlerini eklendi ve n-gram için 1-9 (ortalama harf sayısı) arası tercih edildi.
Kullanılan Modeller:
- Lojistik Regresyon
- Ridge Regresyon
- LightGBM
- XGBoost
- Karar Ağacı
- KNN
- SGD
Modellere ait sonuçlar %20’lik test setinde şu şekilde;
| F1 | Accuracy | Recall | Precision | |
|---|---|---|---|---|
| LGB | 0.927 | 0.969 | 0.914 | 0.940 |
| LR | 0.924 | 0.968 | 0.899 | 0.952 |
| XGB | 0.923 | 0.968 | 0.911 | 0.936 |
| SGD | 0.919 | 0.966 | 0.900 | 0.939 |
| DT | 0.892 | 0.953 | 0.855 | 0.933 |
| Ridge | 0.865 | 0.938 | 0.786 | 0.961 |
| KNN | 0.831 | 0.918 | 0.725 | 0.972 |
Canlıda yapılan denemelerde ise bundan uzak sonuçlar alınıyor. Bahsettiğim gibi amaç streamlit ile arayüzün oluşturulması ve heroku üzerinden de canlıya çıkılması olduğu için bu sefer model başarısını pas geçiyoruz.
Uygulamaya geçmeden önce streamlit’ten de bahsetmek istiyorum. Streamlit özellikle veriye dayalı uygulamalar için hızlıca arayüz oluşturmanızı sağlayan bir Python kütüphanesi. Çok modüler bir yapıya sahip ve title, map, checkbox gibi işinizi inanılmaz kolaylaştıran fonksiyonlara sahip. Dökümanına buradan ulaşabilirsiniz.
Uygulamaya gelecek olursak text_input, select_box, button ve success fonksiyonlarını kullanarak uygulamayı yaratmak mümkün. Geri kalanlar ise tamamen modele ait aşamalar ya da HTML gibi işin önyüz tarafı. Kodu da kısaca anlatmak gerekirse ihtiyacımız olan kütüphaneleri yükledikten sonra modellerin bulunduğu dizini belirtip streamlit’e ait basit ayarları seçiyoruz. Bu ayarlar uygulama adının ne olacağı, uygulamanın sayfadaki konumu gibi değerler. Sonrasında main ile başlayarak öncelikle basit şekildeki önyüzü belirtiyoruz. markdown fonksiyonu bu önyüzün oluşturulmasını sağlıyor. Devamında ise kullanıcıdan alacağımız kelime için text_input ve tahmin yapacak olan model seçimi için select_box bulunuyor. Buna göre seçilen kelime ve model için predictor fonksiyonu belirlenen ve pickle ile çıkarılmış vectorizer‘ı kullanarak sonuç döndürüyor. Sonucun Türkçe veya İngilizce olmasına göre success bize sonucu iletiyor.
import pandas as pd
import numpy as np
from scipy.sparse import hstack, csr_matrix, lil_matrix
import streamlit as st
import pickle
from utils import *
from sklearnwrapper import *
import os, re
path = "model/path"
st.set_page_config(
page_title="Uygulama Adı",
page_icon="",
layout="centered",
initial_sidebar_state="expanded",
)
def main():
# ona minik tasarımlar yapın
html_temp = """
<div style ="background-color:#4169e1; padding:1px">
<h1 style ="color:black;text-align:center;">Kelimeden Dil Tahmini</h1> <br> <br>
</div>
<div>
<p><a href="https://silverstone1903.github.io/posts/2020/07/language-detection-via-words-with-stacking-tr/" target="_blank" rel="noopener">Stacking ile Kelimelerden Dil Tahmini</a> çalışması temel alınarak yapılmıştır. %20'si Türkçe %80'i ise İngilizce'den oluşan kelimeler kullanılarak karakter seviyesinde vektörize edilmiş ve
aşağıda bulunan yöntemler ile 5 kat CV kullanılarak modeller eğitilmiştir. <a href="http://streamlit.io/" target="_blank" rel="noopener">streamlit</a>
ile <a href="heroku.com" target="_blank" rel="noopener">heroku</a> üzerinde canlıya alınmıştır.</p>
<p>Kullanılan Modeller;</p>
<ul>
<li>Lojistik Regresyon</li>
<li>Ridge Regresyon</li>
<li>LightGBM</li>
<li>XGBoost</li>
<li>Karar Ağacı</li>
<li>KNN</li>
<li>SGD</li>
</ul>
<p> </p>
</div>
"""
st.markdown(html_temp, unsafe_allow_html=True)
value = "istatistik"
word = st.text_input("Tahmin edilecek kelimeyi girin:", value)
model = st.selectbox(
"Model Seçin",
(
"Lojistik Regresyon",
"Ridge Regresyon",
"LightGBM",
"XGBoost",
"Karar Ağacı",
"KNN",
"SGD"))
# işte o meşhur yapay zeka (if-else)
if model == "Lojistik Regresyon":
model = model_loader(path + "LogisticRegression.p")
elif model == "LightGBM":
model = model_loader(path + "LGBMClassifier.p")
elif model == "Ridge Regresyon":
model = model_loader(path + "RidgeClassifier.p")
elif model == "SGD":
model = model_loader(path + "SGDClassifier.p")
elif model == "Karar Ağacı":
model = model_loader(path + "DecisionTreeClassifier.p")
elif model == "XGBoost":
model = model_loader(path + "XGBClassifier.p")
elif model == "KNN":
model = model_loader(path + "KNeighborsClassifier.p")
if st.button("Tahmin Et!"):
p1, p0 = predictor(word, model, path + "vectorizer.p")
if p1 > 0.5:
st.success('"{}" %{:.2f} olasılıkla Türkçe'.format(word, 100 * p1))
elif p0 > 0.5:
st.success('"{}" %{:.2f} olasılıkla Ingilizce'.format(
word, 100 * (p0)))
if __name__ == "__main__":
main()
heroku ile de çalışan streamlit uygulamamızı canlıya alıyoruz. Öncelikle Procfile oluşturuyoruz. Procfile uygulamanın nasıl çalışağını belirten bir dosya.
# Procfile
web: sh setup.sh && streamlit run strapp.py
# setup.sh
mkdir -p ~/.streamlit/
echo "\
[general]\n\
email = \"your-email@domain.com\"\n\
" > ~/.streamlit/credentials.toml
echo "\
[server]\n\
headless = true\n\
enableCORS=false\n\
port = $PORT\n\
" > ~/.streamlit/config.toml
Son olarak uygulamada kullandığımız Python kütüphaneleri için gereken requirements.txt‘yi de oluşturduktan sonra uygulamamız heroku’ya göndermek için hazır. Heroku’da deployment için 3 seçenek mevcut. Bu yöntemler; heroku-cli, Github ve heroku-cli ile container registry (docker). Ben bu işe de çok sevdiğim Github-Actions’ı karıştırmak istediğim için Github’ı tercih ettim.
Gelelim Actions aşamasına. Sıklıkla formata dikkat etmeden kod yazan biri olduğum için bir kontrol aşaması ekledim. Böylece kod Github’a push’landıktan sonra FormattingPy çalışarak kod için PEP8 kod formatı kontrolü yapılıyor, eğer format dışı bir yazım varsa bunu düzeltiyor ve düzeltilmiş halini repo’ya push’luyor. Heroku ise actions çalışması bittikten sonra kod düzeltilmesi de yapıldıysa bundan sonra deployment için yeni versiyonu deploy etmeye başlıyor. İlkel bir CI/CD çalışıyor denebilir. Kodun biraz daha çetrefilli hale gelip Class yapısına geçilmesi ile (şu an def‘ler havada uçuşuyor) Python testleri eklemek de mümkün.
# actions.yaml
name: FormattingPy
on: [push]
jobs:
autoyapf:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
with:
ref: $
- name: autoyapf
id: autoyapf
uses: mritunjaysharma394/autoyapf@v2
with:
args: --style pep8 --recursive --in-place .
- name: Check for modified files
id: git-check
run: echo ::set-output name=modified::$(if git diff-index --quiet HEAD --; then echo "false"; else echo "true"; fi)
- name: Push changes
if: steps.git-check.outputs.modified == 'true'
run: |
git config --global user.name github-actions
git config --global user.email '${GITHUB_ACTOR}@users.noreply.github.com'
git remote set-url origin https://x-access-token:$@github.com/$
git commit -am "Automated autoyapf fixes"
git push
Son olarak bu yazıyı yazma motivasyonum Vladimir Iglovikov‘un I trained a model. What is next? yazısıydı. Modeli kurdum sonuçları elde ettim tamam o zaman bittiden sonra yapılabilecek pek çok aşama var aslında. Bu nedenle ben de daha önce yaptığım bir çalışmaya geri dönüp bunu nasıl daha da geliştirebilirim sorusuyla başladım. Bazı ara adımları atlasam da blog yazısı kısmına gelebildim.



