Reco Model Monitoring - FastAPI + Prometheus + Grafana
Published:
![]()
![]()
![]()
![]()
Model Monitoring Nedir?
Uçtan uca (end-to-end) ML çözümlerinde modelin canlıya alınması sonrası bir diğer önemli adım da aslında modellerin izlenmesi. Her ne kadar model olarak bakıyor olsak da aslında bir Rest API oluşturuyoruz ve bu servisi bir şekilde izlememiz gerekiyor. Servisi izleyelim ama bir Rest API’da neleri takip etmek isteriz sorusunu sormamız gerekiyor öncelikle. Benim aklıma gelecek olan sorular aşağıdakiler;
- Zamana göre performansı nasıl? (Peformance Monitoring)
- Gelen isteklere ne kadar sürede yanıt veriliyor? (Response Time)
- Gecikme ne kadar? (Latency)
- Dakikada ne kadar istek geliyor? (Request Per Minute)
- En çok kullanılan API fonksiyonu hangisi?
- Altyapı ne durumda? (Infrastructure)
- Uygulamanın ayakta olup olmadığı (Uptime monitoring)
- Kaynak tüketimi (RAM & CPU)
- Karşılaşılan hatalar neler?
- 4xx ve 5xx hataları
İzleme için ilk olarak neleri bilmek istediğimizi belirlememiz gerekiyor. Yukarıdaki maddeler ağırlıklı olarak bir servisin performansını gözlemlemek için işimize yarayacak olan ölçütler. Bununla birlike ML modeline ait takip etmemiz gereken ölçütler de olacaktır. Örneğin belirli bir zaman aralığındaki tahminlerin ortalama, medyan tahminleri, minimum - maksimum tahminleri ve standart sapmalarını kontrol etmek gerekebilir. Bu bilgilerden faydalanarak modelde/kodda/pipeline’da herhangi bir sorun olup olmadığını gözlemleyebiliriz.
Modeli izlerken gelen istekleri de gözden kaçırmamamız gerekir. Gelen veri istediğimiz gibi mi? Eğer gelen veride bir değişiklik söz konusu ise burada 2 kavram devreye giriyor; data drift ve concept drift. Data drift daha çok gelen veride (x’ler a.k.a bağımsız değişkenler) gerçekleşen değişikliklerden meydana gelirken concept drift x’ler ile birlikte y’nin de değişmesi durumunda ortaya çıkıyor. Şüpheli kullanıcılar data drift için örnek verilebilir. Covid-19 başladığı zaman yarattığı etki ile (telaş, kapanmalar gibi durumlar sonucunda kullanıcı davranışının değişmesi) concept-drift için güzel bir örnek olabilir.
Data drift’in tespit edilmesi için farklı yaklaşımlar bulunmaktadır. En basit ve istatistik içeren yöntemlerden biri olduğu için Kolmogorov-Smirnov (K-S) uyum iyiliği (goodness of fit) testini örnek verebiliriz. İstatistikçesi örneklemin anakütleyi temsil edip etmediğini anlamak olsa da yaptığı iş aslında iki tane dağılımın benzer olup olmadığını (aynı anakütleden gelip gelmediğini) test etmektir. Dolayısıyla bu test ile geçmiş (historical) veri ile yeni veriyi karşılaştırıp farklılık/benzemezlik ölçütüne göre karar vermek mümkün.
Tüm bunların yanı sıra izleme sistemlerinin bize sağladığı en büyük katkı proaktivite! Bu sistemler ile çeşitli alarmlar oluşturarak istenmeyen olası durumlar için daha hızlı önlem alabilir ya da anlık olarak müdahale edebiliriz. Örneğin uptime için kurulacak bir alarm modelin çalışmadığını farketmenizi ve hızlıca müdahale etmenizi sağlayacaktır. Benzer bir şekilde beklenmedik bir zamanda kaynak tüketiminin belirli bir eşiğin üzerine çıkması ile auto-scaling devreye alınarak 5xx hatalarının veya yanıt süresinin yükselmesinin önüne geçilebilir. Bu gibi kriz yaratacak durumların yanı sıra bahsettiğim data/concept drift gibi durumlarda modelin prediyodik eğitim süresini beklemeye gerek kalmadan yeni bir model eğitebilir ya da yeniden eğitim (retrain) ile modeli güncelleyebilirsiniz. Böylece drift etkisinin yaratacağı/yarattığı etkiyi azaltabilirsiniz.

Bu bölümde bahsedilen konular için ileri okuma ve kaynaklar;
- Learning under Concept Drift: A Review
- The Importance of Data Drift Detection that Data Scientists Do Not Know
- Full Stack Deep Learning Lecture 11: Deployment & Monitoring
- How to use Prometheus for anomaly detection in GitLab
- Monitoring Machine Learning Models in Production
- Best Tools to Do ML Model Monitoring
- Challenges of monitoring ML models in production
- A simple solution for monitoring ML systems.
Uygulama
Monitoring girizgahından sonra bu yazıda ne yapacağız? İşbirlikçi filtrelemeden (collaborative filtering) yararlanarak kişi bazlı (user-based) ve ürün bazlı (item-based) benzerlikleri kullanarak öneri yapan bir endpoint oluşturacağız. Bu servisi oluştururken veri işlemleri için pandas’tan Rest API oluşturmak için de FastAPI‘dan yararlanacağız. Servise ait metrikleri almak için Prometheus, bu metrikleri görselleştirmek için de Grafana‘yı kullanacağız. Tüm bunları bir kerede (şakkadanak) ayağa kaldırmak için de docker-compose‘dan yararlanacağız.
Veri Seti
Öneri modeli kuracağım için veri seti olarak UCI ML data repository’de bulunan Online Retail verisinden faydalandım. Literatürde sıkça kullanılan bu veri seti alışveriş işlemlerini içermektedir. Veri ile alakalı diğer bilgileri 2012 yılında yayımlanan Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining makalesinde bulabilirsiniz.
Reco - Modelleme
Aslında bu kısım için modelleme demek çok da doğru değil zira tüm işlemleri benzerlik matrisi üzerinden yaptığımız için veri manipülasyonu içeriyor ve aslında tüm işi pandas yapıyor 😅. Aşağıdaki data_prepare.py script’ini kısaca özetlemek gerekirse veri okunduktan ve temel filtrelemeler yapıldıktan sonra pivot tablodan yararlanılarak müşteri x ürün (4339 x 3665) matrisi oluşturuluyor. Müşteri x ürün matrisi müşterilerin veride bulunan her bir ürün için toplam satın alma sayılarını gösteriyor. Bizim ihtiyacımız olan bilgi ise satın aldı almadı bilgisini temsil edecek olan 0 - 1 olduğu için lambda‘dan faydalanarak bu matrisi 0 ve 1’lerden oluşan (bol bol 0 içeren) bir matrise dönüştürüyoruz.
Müşteri ürün matrisinden faydalanarak ilk olarak müşterilerin birbirlerine ne kadar benzediklerini buluyoruz. Burada benzerlik için kosinüs benzerliğinden (cosine similarity) faydalanıyoruz. Bu matrisimiz ise müşteri sayımız kadar satır ve sütunu sahip (4339 x 4339). Müşteri matrisi ile amacımız birbirine benzer davranışı olan müşterileri bulabilmek. Yine aynı yaklaşımı kullanarak aynı işlemleri ürünler için de yapıyoruz ve 3665 x 3665’lik bir matris daha elde ediyoruz. Son olarak da oluşturduğumuz verileri (matrisleri) pickle formatında data/ klasörü altına kaydediyoruz.
Burada bir not düşmem gerekiyor;
data_preparescript’iniDockerimajı içerisinde çalıştırıyorum. Böylece oluşturulan verilerin boyutları (100 - 150 mb) Docker imajı içerisine oluşturuldukları için imajın boyutunu etkiliyor (ham veri 45 mb). Index işlemlerine üşendiğim içinfeatherformatına getirmedim, format değişikliği ile ufak bir verimlililk artışı mümkün.
# data_prepare.py
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
path = "data/"
df = pd.read_csv(path+'OnlineRetail.csv', dtype={
'CustomerID': str, 'InvoiceID': str}, encoding='unicode_escape')
df = df.loc[df['Quantity'] > 0]
df = df.dropna(subset=['CustomerID']).reset_index(drop=True)
customer_item_matrix = df.pivot_table(
index='CustomerID',
columns='StockCode',
values='Quantity',
aggfunc='sum')
customer_item_matrix = customer_item_matrix.applymap(
lambda x: 1 if x > 0 else 0)
user_user_sim_matrix = pd.DataFrame(cosine_similarity(customer_item_matrix))
user_user_sim_matrix.columns = customer_item_matrix.index
user_user_sim_matrix['CustomerID'] = customer_item_matrix.index
user_user_sim_matrix = user_user_sim_matrix.set_index('CustomerID')
item_item_sim_matrix = pd.DataFrame(cosine_similarity(customer_item_matrix.T))
item_item_sim_matrix.columns = customer_item_matrix.T.index
item_item_sim_matrix['StockCode'] = customer_item_matrix.T.index
item_item_sim_matrix = item_item_sim_matrix.set_index('StockCode')
user_user_sim_matrix.to_pickle(path+'user_user_sim_matrix.p')
item_item_sim_matrix.to_pickle(path+'item_item_sim_matrix.p')
customer_item_matrix.to_pickle(path+'customer_item_matrix.p')
df.to_pickle(path+'df.p')
Reco - Öneri Aşaması
Öneri aşamasında müşterilere öneri yapılırken ilgili müşterinin (A) id’si alınıyor ve müşteri benzerlik matrisinden yararlanılarak en yüksek benzerliğe sahip müşteri (B) seçiliyor. B müşterisinin satın aldığı ama A müşterisinin satın almadığı ürünler A müşterisine öneri olarak sunuluyor. Buradaki dezavantajlardan biri müşterilerin satın aldığı ürünlerin benzer olması ve satın alma sayılarının yakın olması durumunda yapılabilecek öneri çeşitliliği (dolayısıyla sayısı) azalıyor. Buna önlem olarak popüler ürün önerisi gibi fallback senaryolar düşünülebilir. Böylece n tane öneri getir durumunda eksik olan öneriler tamamlanabilir.
Ürün önerisi için ise çok daha basit bir kurgu işliyor. Ürün matrisi ilgili ürün id’si için filtreleniyor. Benzerlikler çoktan aza olacak şekilde sıralanıyor ve ilk n tanesi öneri olarak sunuluyor.
Önerilerin nasıl yapıldığı ile ilgili fonksiyonlar utils.py içerisinde görülebilir.
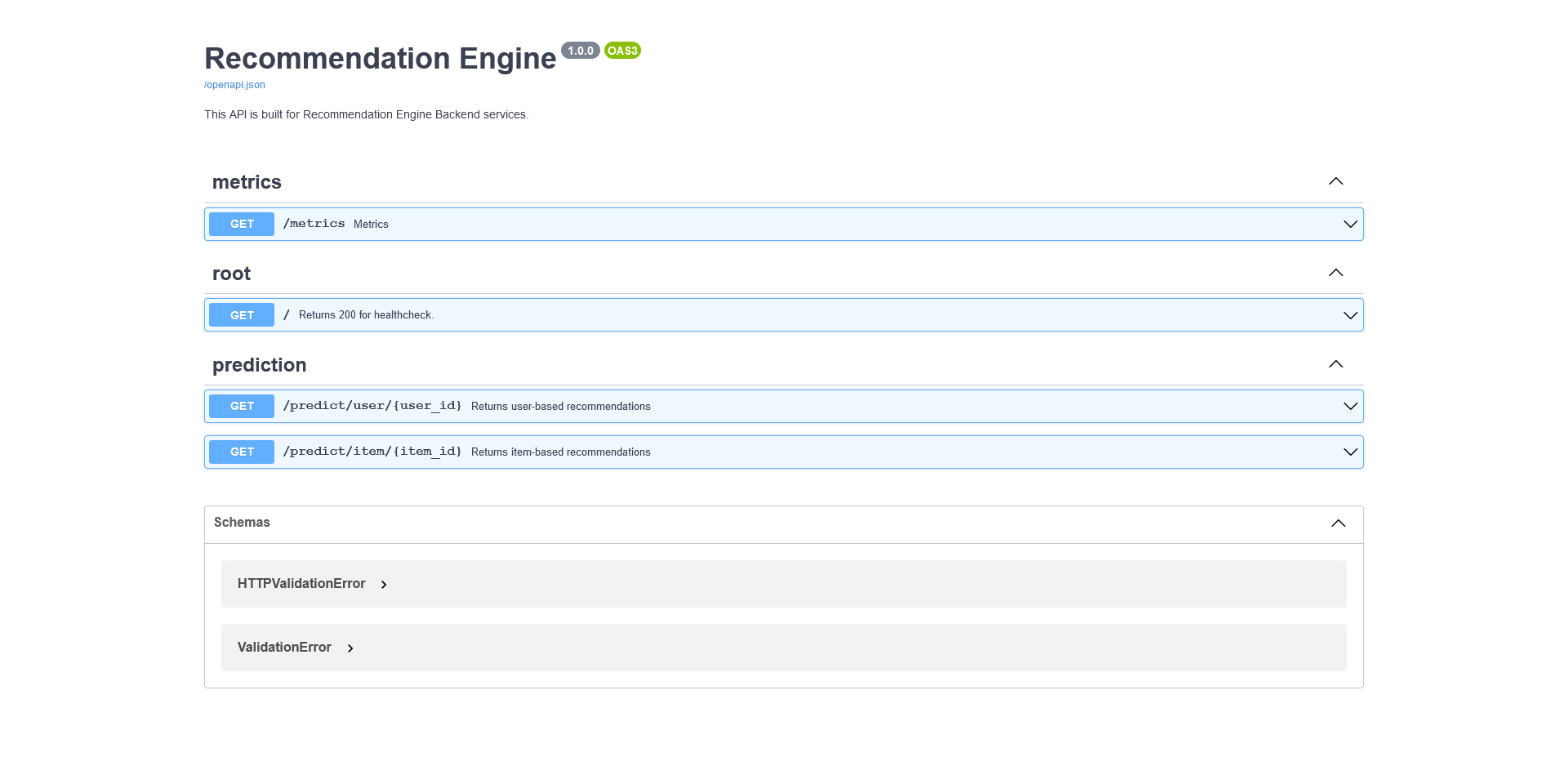
FastAPI
FastAPI temelde yardımcı fonksiyonlardan (utils.py) faydalanarak tahmin sonuçlarını döndürüyor. İlk başta kurgularken POST isteği ile ilgili müşteri ya da ürün id’sinin atılması ve ona göre sonuç dönülmesi şeklinde kurgulamıştım fakat daha sonra sorgu parametreleri (query parameters) kullanmak için GET olacak şekilde değiştirdim. Yine POST için sadece predict endpoint’i olacakken (müşteri ve ürün id’leri farklı, arkada if ile yönetmek gerekecek) bu değişiklik ile item ve user için iki ayrı endpoint oluşturabildim. Oluşturduğum endpoint’lere toplam kaç sonuç dönüleceğini de sorgu parametresi olarak ekledim. Varsayılan olarak ürün ve müşteri için 5 sonuç dönülüyor. Sorgu sonuna eklenecek n parametresi ile de sonuç sayısı değiştirilebiliyor.
http://localhost:8000/predict/item/item_id?n=50
http://localhost:8000/predict/user/user_id?n=50
API metriklerini iletmek için detayına bir sonraki başlıkta değineceğim prometheus_fastapi_instrumentator‘dan yararlanıyoruz.
# app.py
import pandas as pd
from fastapi import FastAPI
from prometheus_fastapi_instrumentator import Instrumentator, metrics
from utils import *
APP_VERSION = "1.0.0"
APP_NAME = "Recommendation Engine"
API_PREFIX = "/"
NAMESPACE = "recommendation_engine"
SUBSYSTEM = "online_store"
DATA_PATH = "data/"
user_user_sim_matrix = pd.read_pickle(DATA_PATH+'user_user_sim_matrix.p')
item_item_sim_matrix = pd.read_pickle(DATA_PATH+'item_item_sim_matrix.p')
customer_item_matrix = pd.read_pickle(DATA_PATH+'customer_item_matrix.p')
df = pd.read_pickle(DATA_PATH+'df.p')
app = FastAPI(title="Recommendation Engine", version=APP_VERSION,
description="This API is built for Recommendation Engine Backend services.")
instrumentator = Instrumentator(
should_group_status_codes=False,
should_ignore_untemplated=True,
should_respect_env_var=True,
should_instrument_requests_inprogress=True,
excluded_handlers=["/metrics", "/metrics/"],
env_var_name="ENABLE_METRICS",
inprogress_name="inprogress",
inprogress_labels=True)
...
Instrumentator().instrument(app).expose(app, tags=["metrics"])
@app.get("/", status_code=200, summary="Returns 200 for healthcheck.", tags=["root"])
def index():
return {"staus": "ok"}
@app.get("/predict/user/{user_id}", summary="Returns user-based recommendations", response_description="User Based Recommendation Results.", tags=["prediction"])
async def predict(user_id: str = '12350', n: int = 5):
pred = recommend_customer(user_user_sim_matrix,
customer_item_matrix, df, user_id, n=n)
return {"success": True, "type": "user_based", "total": n, "data": {user_id: str(pred)}}
@app.get("/predict/item/{item_id}", summary="Returns item-based recommendations", response_description="Item Based Recommendation Results.", tags=["prediction"])
async def predict(item_id: str = '23166', n: int = 5):
pred = get_similar_items(item_item_sim_matrix, item_id, n=n)
return {"success": True, "type": "item_based", "total": n, "data": {item_id: str(pred)}}
Prometheuss + Grafana
Prometheus exporter‘lardan yararlanarak belirlenen adreslere HTTP istek atarak sonuçları kendi zaman serisi (time-series) veritabanına kaydederek çalışan bir araç. Kaydedilen bu bilgiler genellikle PromQL kullanılarak prometheus arayüzünden ya da Grafana gibi dashboard’lar üzerinden takip edilir.
Aldığınız metriklere bağlı olarak PromQL bir hayli karmaşık hale gelebiliyor. Basit ve hızlı bir başlangıç yapmak için PromQL for Humans yazısına göz atabilirsiniz.
Grafana açık kaynak kodlu ve hızlıca veri kaynağına entegre olabilen bir veri görselleştirme arayüzüdür. AWS CloudWatch, PostgreSQL, Prometheus, ElasticSearch gibi pek çok farklı veri kaynağına erişebilmektedir. Ayrıca Alerts mekanizmasıyla da kural setleri oluşturularak alarm gönderilebilmektedir. Örneğin up sorgusu x dakikadır sinyal almıyorsa Microsoft Teams’teki Alert kanalına mesaj gönder gibi. Prometheus + Grafana ikilisi ise yazılım uygulamalarını izlemek için sıklıkla birlikte kullanılmaktadır.
Yukarıda da bahsettiğim gibi FastAPI uygulamasından metrikler alınacağı ve Prometheus’a gönderileceği için prometheus_fastapi_instrumentator paketinden yararlanıyoruz. Bu paket FastAPI için prometheus-python client‘ını kullanarak exporter görevi görüyor ve /metrics endpoint’ini oluşturuyor. İstersek kendi metriklerimizi de ekleyebiliyoruz.
Uygulamayı Ayağa Kaldırma
Daha önce IAS olarak kurduğum bu sistemi tek tek uğraşmamak adına compose ile kurmayı tercih ettim. IAS olarak kurduğum dönemde karşıma çıkan ama Docker kuramadığım için (Virtualization ayarı kapalı olan bir uzak sunucu) kullanamadığım bir repo‘dan yararlandım. Repo’daki kurgu basit bir FastAPI uygulaması için kurgulandığından dolayı bazı değişiklikler yapmam gerekti. Dockerfile’da imajı python:3.8.8-slim olacak şekilde güncelledim böylece imajın boyutundan bir hayli tasarruf edebildim. Grafana için dashboard.json ve datasource.yml dosyalarında değişiklikler yapmam gerekti ve bu yeni değişiklikler için compose içeriğini de güncelledim.
Uygulamayı ayağa kaldırmak için ihtiyacımız olan 2 şey var;
Docker ve docker-compose kurulu ise aşağıdaki adımlar ile uygulamayı ayağa kaldırabilirsiniz.
git clone https://github.com/silverstone1903/reco-model-monitoring
docker-compose up -d
Docker-compose ile uygulama sorunsuz bir şekilde ayağa kalktıysa aşağıdaki adreslerden API healthcheck sayfasına, Prometheus arayüzüne ve Grafana’ya erişebilirsiniz.
- FastAPI: http://localhost:8000
- Prometheus: http://localhost:9090
- Grafana: http://localhost:3000
Repo: silverstone1903/reco-model-monitoring
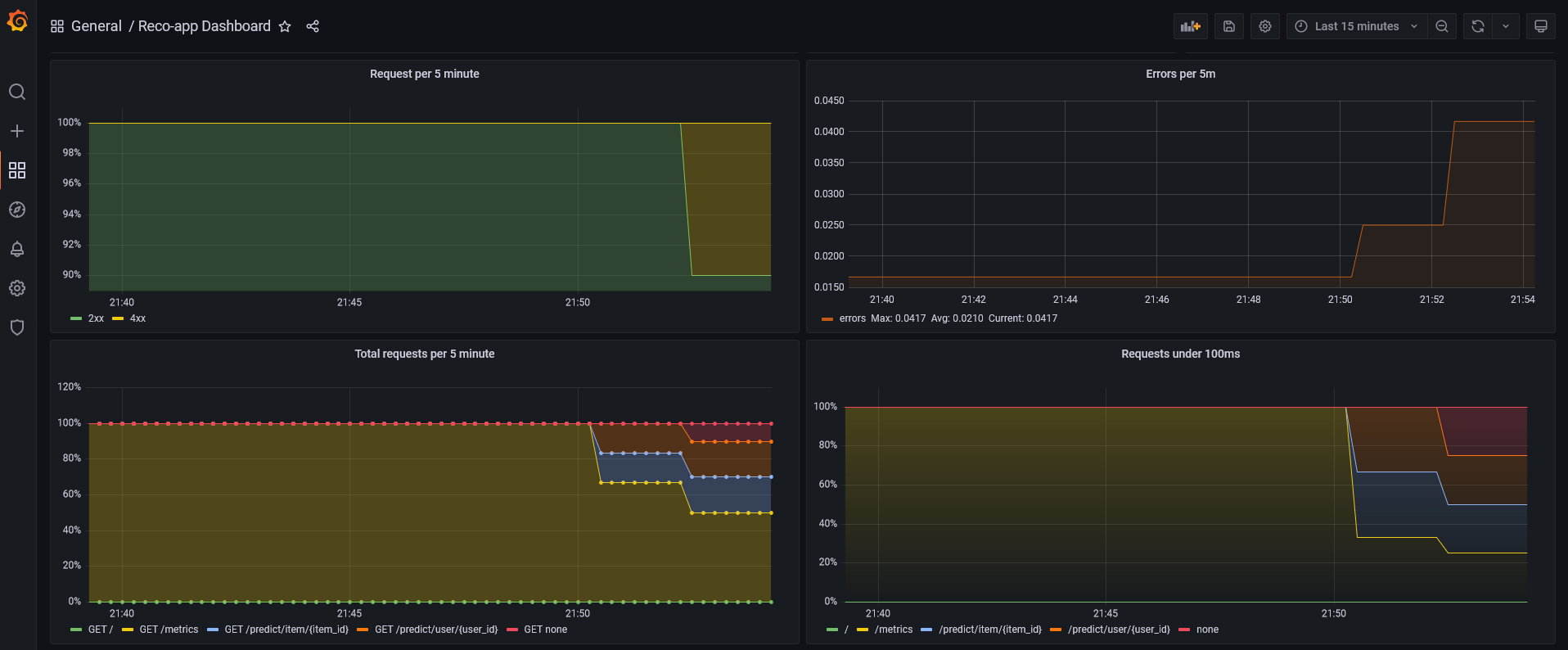
Uygulama arayüzüne ait ekran görüntüleri 👇🏻
Grafana
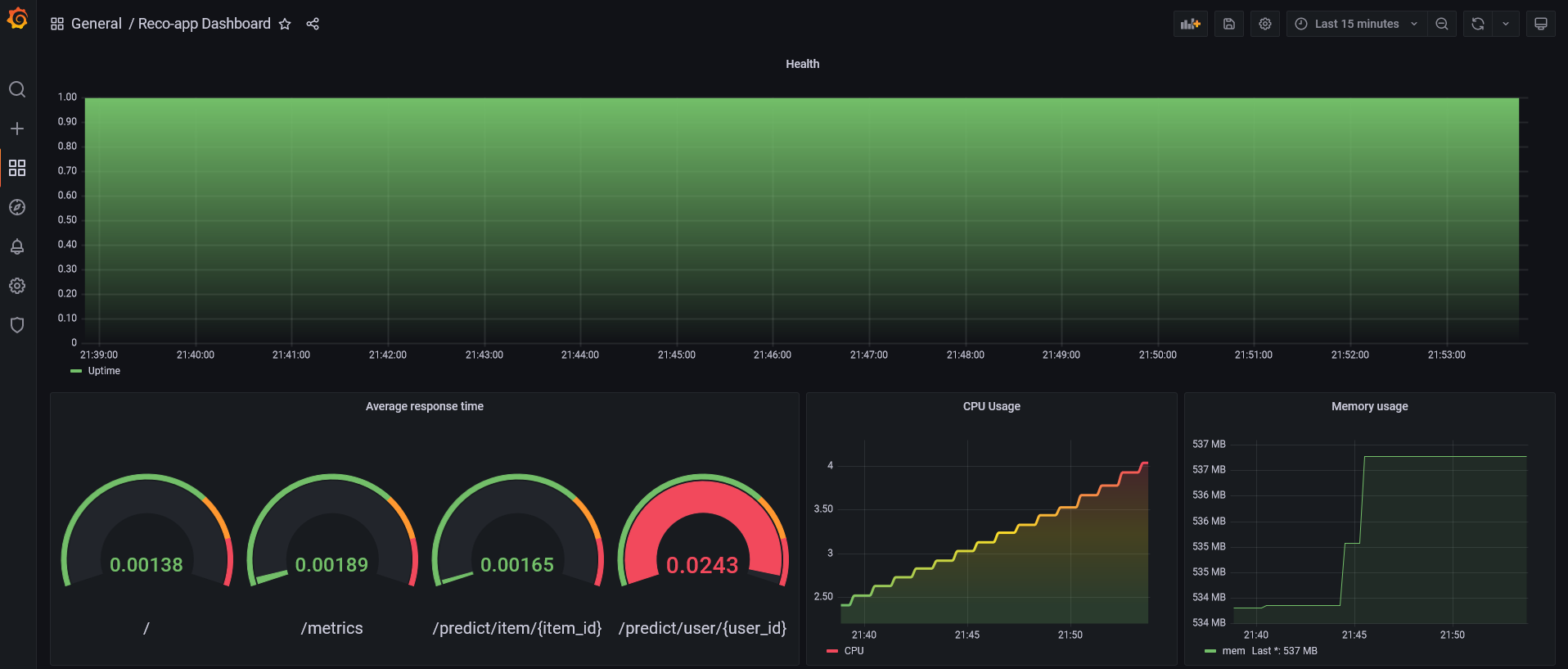
Endpoint’e ait sonuçlar


FastAPI Docs