
Stream Veriye Giriş: Kafka, Spark ve AWS Glue ile Küçük Veri İşleme
Published:
![]()


Daha önce stream veri ile hiç çalışmadığım için basit bir senaryo yaratıp Apache Kafka, Apache Spark ve AWS Glue kullanarak büyük oranda IAS olan bir yapı kurdum. Bu senaryoda kaynaktan periyodik olarak gelen veri kafka’ya gönderiliyor ve oradan Spark’a aktarılıyor. Spark’ta veri basitçe işlenip S3’e parquet formatında yazılıyor. Son olarak yazılan ham veri ise Glue ile tek parça olarak (repartition(1)) tekrar S3’e parquet formatında yazılıyor ve Athena‘ya tablo olarak aktarılıyor.
Kafka
Kafka, temelde akan verinin gerçek zamanlı olarak alınmasını/işlenmesini ölçeklenebilir (scalable) ve dağıtık (distributed) şekilde sağlayan bir araçtır (gereksiz detay: LinkedIn tarafından 2011 yılında geliştirilmiştir). Akan verinin işlenmesi, gerçek zamanlı analitik veya akan veride ETL gibi senaryolar ile analitik işlere göz kırpan bir araç gibi görünse de “event-driven” mimariye sahip mikroservisler için de sık tercih edilen bir araçtır.
Kafka’yı ayağa kaldırmak için ilk olarak EC2 üzerinden Amazon AMI ile bir sunucu yaratıyoruz (t3.xlarge/t3.large/t3.medium seçebilirsiniz). Daha önce EC2 ile sunucu oluşturmadıysanız buraya göz atabilirsiniz. Sunucuya ssh ile bağlandıktan sonra kafka’yı indiriyoruz ve Java’yı kuruyoruz.
wget https://downloads.apache.org/kafka/3.5.1/kafka_2.12-3.5.1.tgz # 2.12 scala versiyonu
tar -xvf kafka_2.12-3.5.1.tgz
mv kafka_2.12-3.5.1.tgz kafka
sudo yum install java-1.8.0-amazon-corretto
sudo yum install java-1.8.0-amazon-corretto-devel
Kafka’yı tar dosyasından çıkardıktan sonra kafka dizinine giriyoruz ve zookeeper‘ı başlatıyoruz.
cd kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
Zookeeper’ı başlattıktan sonra yeni bir terminal penceresi açıp kafka’yı başlatmak için sunucunun ip adresini config/server.properties dosyasına ekliyoruz. Bunun için sudo nano config/server.properties komutu ile advertised.listeners=PLAINTEXT://**kafka_ip**:9092 satırını ekliyoruz (sunucuya ait olan security group’ta 9092 port’u için erişim tanımlamayı unutmayın!) ve aşağıdaki komutu çalıştırıyoruz.
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
bin/kafka-server-start.sh config/server.properties
Böylece hem zookeeper hem de kafka ayağa kalkmış oluyor. Öncelikle kafka için bir topic oluşturmak gerekiyor. Bunun için yeni bir terminal penceresi ile aşağıdaki komutu çalıştırıyoruz ve kafka stream için hazır hale geliyor.
bin/kafka-topics.sh --create --topic customer_data --bootstrap-server ec2_ip:9092 --replication-factor 1 --partitions 1
Producer
Sırada producer.py script’ini çalıştırmak var. Bu script ile kafka’ya sürekli olarak veri gönderiyoruz. Faker paketini kullanarak basit bir kullanıcı verisi oluşturuyoruz ve rastgele aralıklar ile customer_data‘ya veri gönderiyoruz.
Spark Streaming
Kafka ayakta, producer çalışıyor ve artık yazılan veriyi okuyabiliriz. Spark Structured Streaming dolu dolu bir dokümana sahip. Neyse ki kafka’yı varsayılan bir şekilde desteklediği için readStream fonksiyonu ile kolayca stream’e bağlanıp veri okumak mümkün. Fakat öncesinde benim de bir hayli uğraştığım bir kısımdan bahsetmem gerekiyor. Spark’ı ayağa kaldırırken kafka-clients, hadoop-aws ve spark-sql-kafka paketlerine ihtiyacımız var. Bu paketleri maven üzerinden indirebiliyoruz fakat spark sürümü ve hadoop sürümü ile çakışma sorunu yaşanabiliyor, beni biraz uğraştırdı 😅
Geliştirmeye ilk başta kendi lokalimde başlamıştım fakat hem paketlerden hem de Windows kaynaklı hadoop sorunundan dolayı spark için de EC2 üzerinde ayrı bir sunucu oluşturdum. spark_consumer.py script’inde yukarıda bahsettiğim paketleri kurarak spark context’i ayağa kaldırıyoruz ve S3 bucket’ına erişebilmek için gerekli olan ayarları tanımlıyoruz. readStream ile kafka sunucusunu, topic adını tanımlayıp kafka’dan veri okumaya başlıyoruz. Bu adıma kadar her şey sorunsuz ise okuduğumuz ham verinin formatı aşağıdaki gibi 👇🏻
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
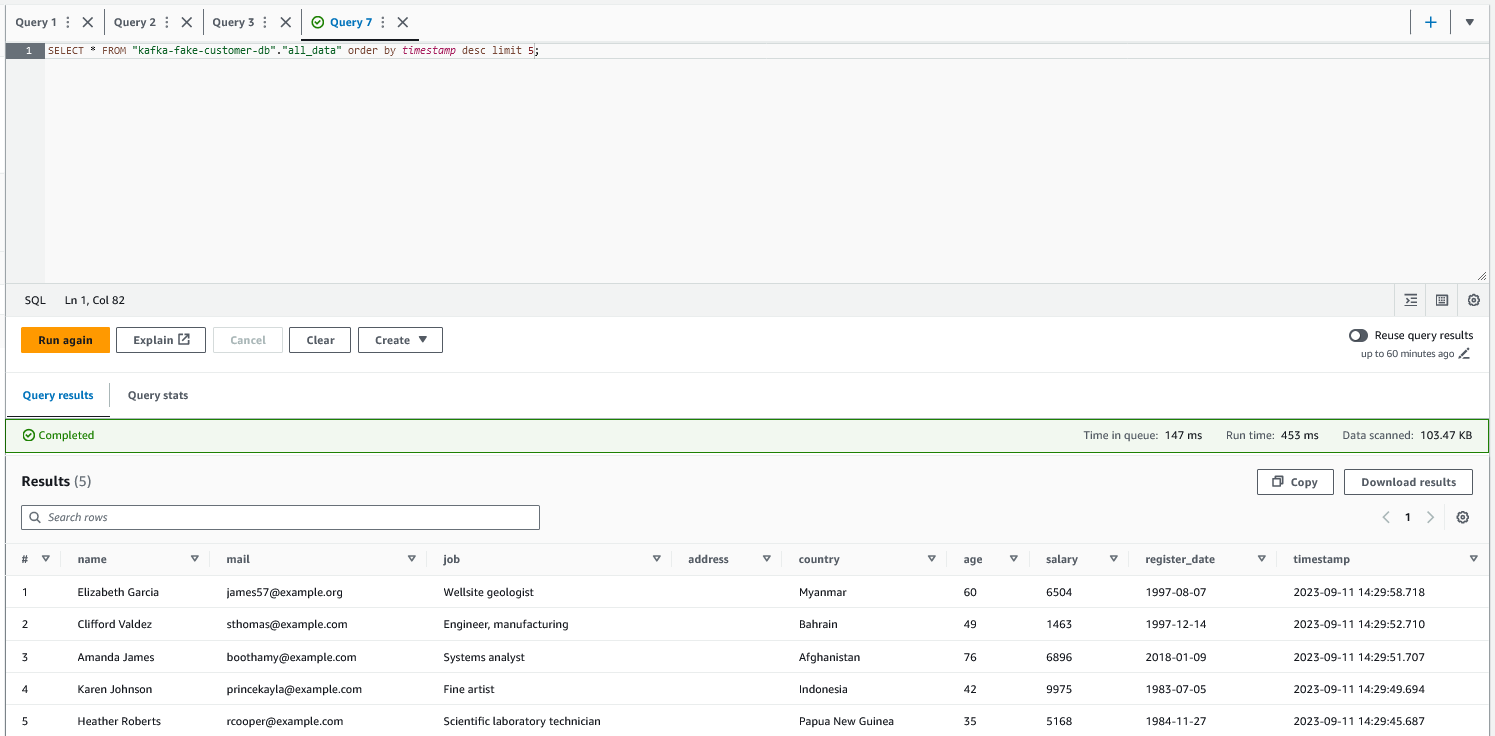
Bizim ilgilendiğimiz kısım value içerisinde. O nedenle basit bir şema (schema) tanımlayıp veriyi value içerisinden çıkaracak select fonksiyonu yazarak ilgili veriyi data.frame haline getiriyoruz. Böylece yeni şemamız aşağıdaki gibi oluyor 👇🏻
root
|-- name: string (nullable = true)
|-- mail: string (nullable = true)
|-- job: string (nullable = true)
|-- address: string (nullable = true)
|-- country: string (nullable = true)
|-- age: integer (nullable = true)
|-- salary: integer (nullable = true)
|-- register_date: date (nullable = true)
|-- timestamp: timestamp (nullable = true)
Artık gelen veri S3’e yazılmaya hazır. writeStream kullanarak veriyi yazacağımız S3 dizinini belirliyoruz ve gelen hangi aralıkla yazılacağını trigger(processingTime="60 seconds") ile belirliyoruz. Böylece her 60 saniyede bir veri S3’e parquet formatında yazılacak. Son olarak option("checkpointLocation", "s3a://bucket_name/checkpoint") ile checkpoint dizinini belirliyoruz. Checkpoint dizini spark’ın veriyi yazarken hata alması durumunda veriyi tekrar yazmaması için kullanılıyor.
AWS Glue
Verimiz artık her 60 saniyede bir tanımladığımız S3 bucket’ına yazılıyor. Bu senaryoda dakikada bir parquet dosyası yazıldığı için sürekli farklı boyutta dosyalar oluşuyor. Bunları tek bir parquet dosyası haline getirip Athena’dan sorgu atabileceğimiz tek bir tablo haline getirmek için AWS Glue kullanıyoruz. Glue, AWS üzerinde ETL işleriniz için kullanabileceğiniz serverless bir servis. Glue ile ilgili detaylı bir doküman burada mevcut.
Glue ETL altında farklı yöntemler ile ETL işleri oluşturabiliyorsunuz. Canvas üzerinden sürükle-bırak formatına benzer bir görsel arayüz (Visual ETL) ile veri akışını (data-pipeline) kolayca tanımlayabilirsiniz. Bunun yanı sıra spark script ile çalışmak isterseniz ya da notebook kullanmak isterseniz de bu seçenekler mevcut. Ben bu senaryoda notebook ile çalışmayı tercih ettim, daha doğrusu etmek durumunda kaldım çünkü spark stream ile veri yazılırken ham verinin olduğu klasörde _spark_metadata adında stream’e ait metadata’nın bulunduğu bir klasör oluşuyor. Bu klasör varken Visual ETL ile veri okumak mümkün değil (Hata: An error occurred while calling o89.getDynamicFrame. s3://path/to/data/_spark_metadata/0 is not a Parquet file.). Bu nedenle notebook kullanarak spark context yaratıp ve ilgili klasördeki parquet dosyalarını okuyarak repartition‘dan yararlanıp tek bir parquet dosyası haline getiriyoruz ve S3’teki processed_data klasörüne yazıyoruz. Veri yazıldıktan sonra Yine Glue içerisinde bulunan Crawlers sekmesine giderek Athena’ya veri yazacak olan crawler’ı oluşturuyoruz ve run diyerek çalıştırıyoruz. Bu işlem sonrasında Athena’da veriye erişebiliriz.
Son olarak başta da bahsettiğim gibi yapı IAS (Infrastructure as a Service) olduğu için biraz uğraştırıcı olabiliyor. Akan veriye giriş adına kurguladığım için hızlı ve geçici (“quick & dirty”) bir çözüm olarak geliştirmeye başladım. Fakat bu yapıyı kurduktan sonra veri akışı otomatik bir şekilde gerçekleşiyor ve veriye erişmek için ekstra bir işlem yapmanıza gerek kalmıyor. Yine de, hem kafka hem de spark adımlarını Dockerize etmek ve AWS üzerinde ECS ile çalıştırmak (veya Apache MSK ile Glue Stream kullanmak) daha iyi bir seçenek olabilir. Ve yine Glue üzerindeki işlemler de elle tetikleniyor, bu işlemleri de otomatize etmek ve tüm yapıyı baştan sonra bir veri akışı (data pipeline) olarak kurgulamak mümkün.
Github: stream-101
Kullanılan Sürümler
- Python 3.7.12
- Spark 3.2.4
- pyspark 3.2.4
- Scala 2.12
- Hadoop 2.7.4
- Kafka 3.5.1
Ekran Görüntüleri
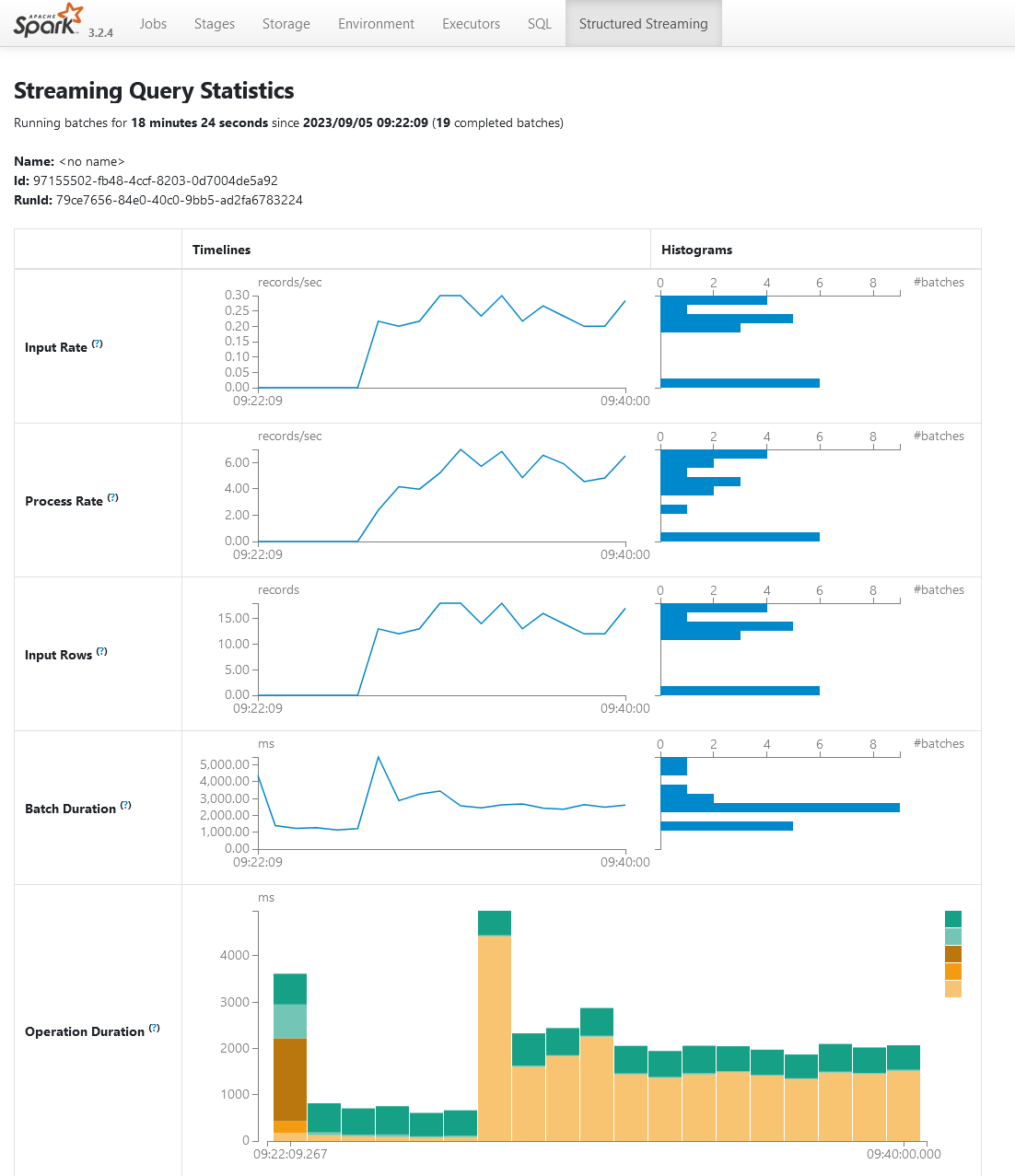
Spark Structured Streaming UI
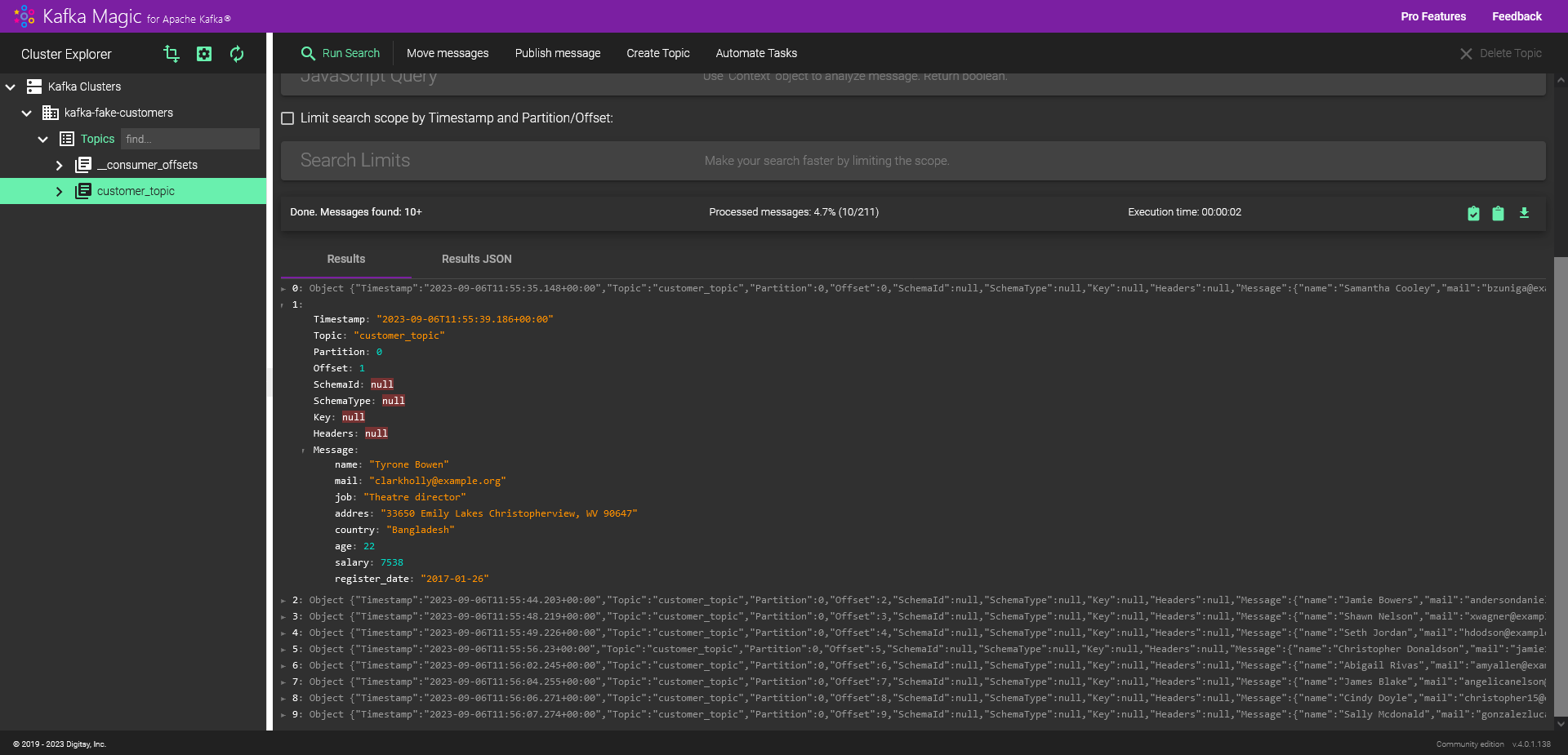
Kafka Topic’lerini takip edebileceğiniz arayüz: Kafka Magic


