Sagemaker-101: Modelleme ve Canlıya Alma (λ ile Serverless)
Published:
![]()
Bu yazıda AWS Sagemaker’a basit ve hızlı bir giriş yapacağız. Sagemaker kullanarak XGBoost ile modelleme ve modelin canlıya alma (deployment) işlemlerini gerçekleştireceğiz. Modelimizi canlıya almak için Sagemaker endpoint’ine ek olarak Lambda ve API Gateway servislerini kullanacağız. İlk olarak Sagemaker nedir, ne için ve nasıl kullanılır ona bakalım.
Sagemaker Nedir?
Sagemaker, AWS tarafından geliştirilen ve makine öğrenmesi modellerinin geliştirilmesi, eğitilmesi ve dağıtılması (deployment) için kullanılan ve SaaS (Software as a Service) olarak çalışan bir servistir (AI/ML as a service -AIaaS- diyenler de mevcut). AWS tarafından 2017 yılında yapılan re:Invent‘te kullanıma sunulmuştur.
Sagemaker ile veri setlerini işleyebilir, model kurabilir ve model performansını izleyebilirsiniz. Aynı zamanda Sagemaker ile modelinizi AWS üzerinde deploy edebilir ve modelinizi AWS üzerinde kullanabilirsiniz. En temel avantajlarında biri uçtan uca veri, modelleme ve canlıya alma işlemlerini tek bir servis üzerinden yapabilmenizdir. Kısaca Sagemaker için bir ML platformu demek mümkün.
Sagemaker kullanmak için Sagemaker Studio ya da Sagemaker Canvas kullanabilirsiniz. Studio, Sagemaker’ın gelişmiş bir IDE’sidir. Studio ile kod yazarak veri setlerini işleyebilir, temizleyebilir feature store kullanabilir ya da tüm modelleme aşamalarını gerçekleştirip modeliniz canlıya abilirsiniz. Canvas ise Sagemaker’ın görsel bir arayüze sahip (no-code), sürükle bırak ile çalışan halidir ve daha çok teknik olmayan kullanıcılar için uygundur.
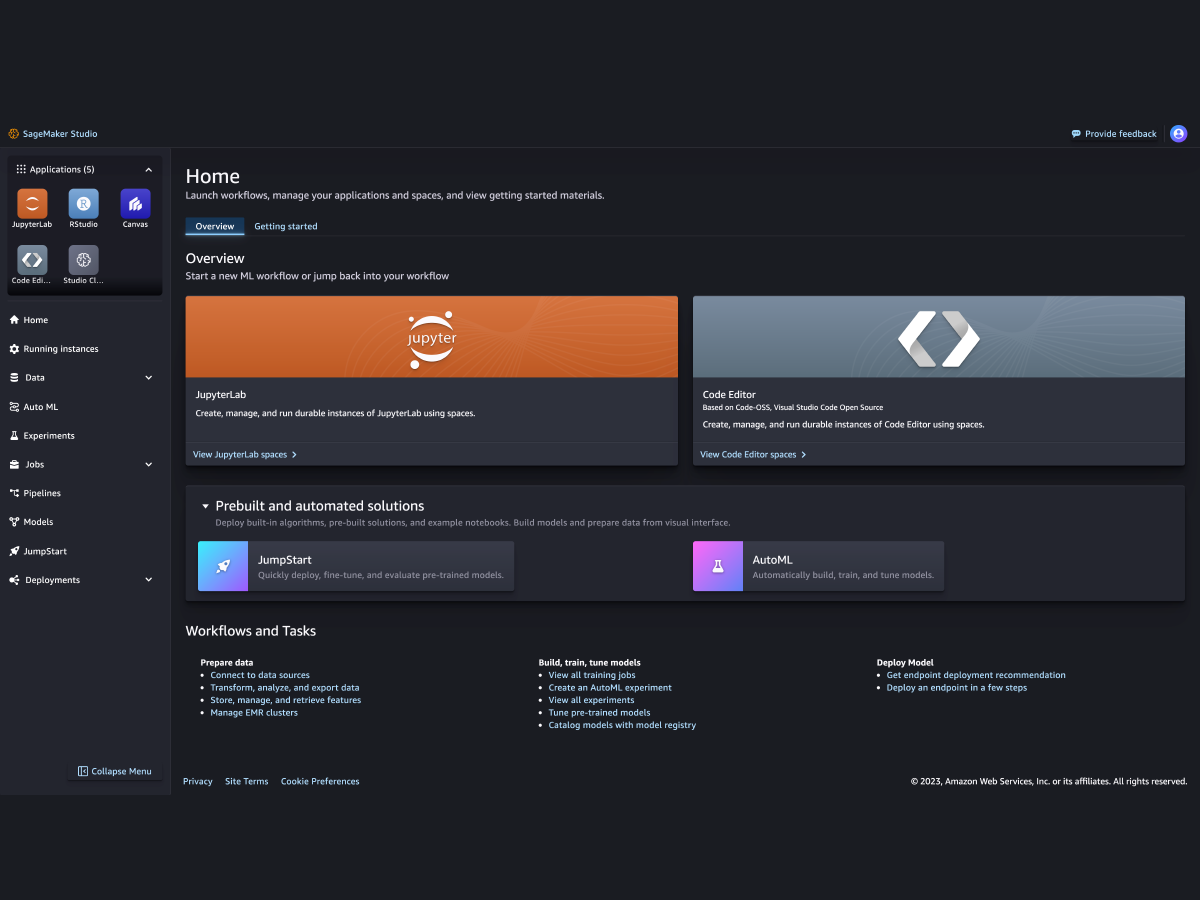
Sagemaker Studio - Kaynak: AWS
Sagemaker Studio içerisinde farklı fonksiyonlara sahip servisler bulunmaktadır. Bu servislerden bazıları aşağıdaki gibidir;
- Data Wrangler
- Veri hazırlığı için kullanabileceğiniz basit bir arayüzdür. Veri setlerini birleştirebilir, temizleyebilir, feature store kullanabilirsiniz.
- Auto Pilot
- AutoML servisidir. Veri setinizi seçip belirli seçimleri (hedef değişken vb.) yaptıktan sonra Auto Pilot ile veri setinizi otomatik olarak işleyebilir ve model kurabilirsiniz.
- JumpStart
- Önceden eğitilmiş (pre-trained) modelleri kullanabileceğiniz bir servistir. Farklı senaryolar için (metin/görsel sınıflama, metin/görsel üretme vb.) farklı modelleri tek tuşla deploy veya fine-tune edebilirsiniz.
Bunların yanı sıra AWS konsolu üzerinden de görebildiğiniz Deployments, Models, Experiments gibi sekmeler bulunmaktadır. Buradan modellerinizi, pipeline’larınızı, endpoint’lerinizi ve daha fazlasını yönetebilirsiniz. AWS konsolunda Sagemaker altında ise bazıları Studio’da da bulunan Training, Inference, Ground Truth, Governance gibi sekmeler bulunmaktadır. Bu sekmelerden de training job’larını görebilir, endpoint’lerinizi yönetebilir veri etiketleme (data labelling) işleri oluşturabilirsiniz.
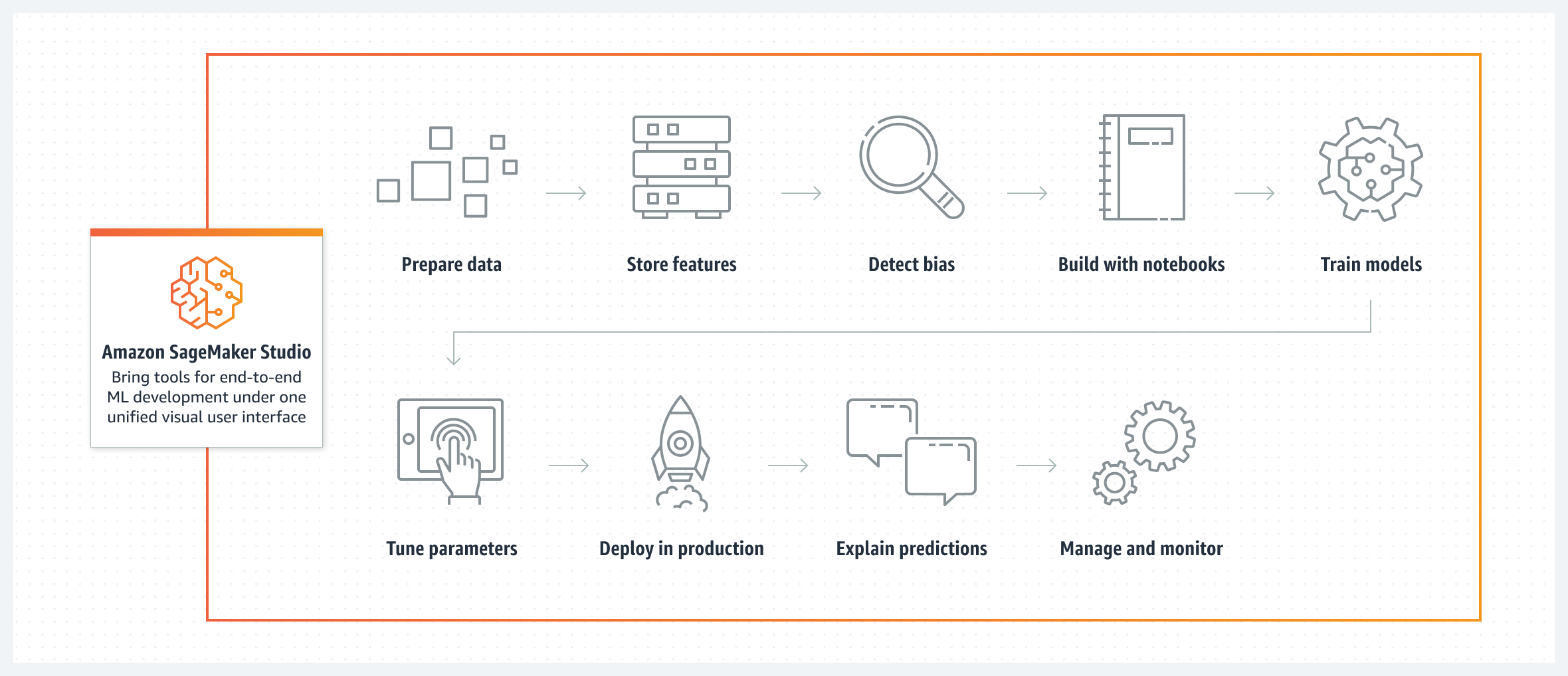
How it works - Kaynak: AWS
Sagemaker’ı bu jenerik tanımlamalar olmaksızın açıklamak zor. Nasıl ki Lambda’yı event-driven senaryolarda rahatlıkla kullanabileceğiniz gibi ETL, gerçek zamanlı bildirim, e-mail gönderimi vb. senaryolarda da kullanabiliyorsanız aynısı Sagemaker için de geçerli. Sagemaker ile ML projelerinde dokunabildiğiniz her alana dokunabilirsiniz. Verinin basitçe işlenmesinden modelin kurulmasına, modelin izlenmesine (model monitoring), model çıktılarının açıklanmasına (XAI - Explainable AI) data/concept drift takibinin yapılmasına ve buna bağlı olarak modelin tekrar eğitilmesine veya uçtan uca akışların (pipelines) oluşturulmasına kadar birçok işlemi Sagemaker üzerinde yapabilir ve bunları otomatize edebilirsiniz.
Sagemaker konsol desteğinin yanında API, CLI ve SDK için de destek sunmaktadır. Bu sayede Sagemaker’ı başka uygulamalarınız içinde de çağırabilirsiniz. Desteklediği diller arasında Python, Java, Javascript, Go gibi diller bulunmaktadır. Desteklenen dillere ve dokümanlarına buradan ulaşabilirsiniz.
Sagemaker’a giriş yapmak isterseniz aşağıdaki kaynaklara göz atabilirsiniz:
- Amazon SageMaker Workshop
- Amazon SageMaker End to End Workshop
- Amazon Sagemaker Workshop
- SageMaker Immersion Day
- Amazon SageMaker 101 Workshop
Not: Herhangi bir AWS servisi kullanmadan önce yapmanız gereken en önemli şey fiyatlandırma politikasına bakmak. O nedenle buradan 😅.
Modelleme & Deployment
Bu çalışmamızda yukarıda bahsettiğim üzere Sagemaker Studio üzerinde model kuracağız ve modelimizi canlıya alacağız. Daha önce MLOps Nedir? Github Actions ile CML yazımda kullandığım IBM HR Analytics Employee Attrition & Performance veri setini kullanarak XGBoost ile model kuracağız. Amaç model başarımından çok Sagemaker ekosisteminin nasıl kullanıldığını göstermek olduğu için veri ve modelleme kısmını kısa tutacağım.
Verinin okunması ve işlenmesi kısımlarını fastapi + MLflow + streamlit + AWS = MLOps yazımda kullandığım fonksiyonlar ile yapacağım ve bu nedenle de çok fazla detaya girmeyeceğim. Verinin işlenmesi ve modelin kurulmasına ait kodların tamamına buradan ulaşabilirsiniz.
Kabaca notebook’u özetlemek gerekirse veri setini okuyoruz ve gerekli önişleme adımlarını uyguluyoruz. Veri setini işlerken veriyi train, test ve validasyon olarak ayırıyoruz. Daha sonra train setini kullanarak XGBoost ile model kuruyoruz. Modelleme tamamlandıktan sonra test seti üzerinde model başarımını ölçüyoruz. Bir dipnot; kullandığımız XGBoost, Sagemaker altındaki XGBoost implementasyonu. Bu nedenle XGBoost’un kendi implementasyonu ile kullanım farklılıkları mevcut.
İlk olarak verimizi hazırladıktan sonra Sagemaker train job’ının veriye erişebilmesi için train ve validasyon verimizi belirlediğimiz S3 bucket’ına yüklüyoruz.
import sagemaker
sess = sagemaker.Session()
pd.concat([y_train, x_train], axis=1).to_csv('train.csv',
index=False,
header=False)
sess.upload_data(path='train.csv',
bucket=bucket,
key_prefix=prefix+'/train')
Daha sonra Sagemaker train job’ı için TrainingInput objelerini (train ve validasyon) oluşturuyoruz. TrainingInput objeleri S3 üzerindeki veriye erişim için kullanılıyor.
from sagemaker.inputs import TrainingInput
s3_input_train = TrainingInput(s3_data=f's3://{bucket}/{prefix}/train',
content_type='csv')
Train aşamasına geçmeden önce Estimator objesi için gerekli olan değişkenleri (region, instance type, container vb.) tanımlıyoruz ve objeyi oluşturuyoruz.
import boto3
region = boto3.Session().region_name
role = sagemaker.get_execution_role()
instance_type = 'ml.m4.xlarge'
container = sagemaker.image_uris.retrieve(framework="xgboost", region=region, version="latest")
from sagemaker.estimator import Estimator
xgb = Estimator(container,
role,
sagemaker_session=sess,
instance_count=1,
instance_type=instance_type,
input_mode='File',
output_path=f's3://{bucket}/{prefix}/output',
train_use_spot_instance=True
)
Son olarak ise modellemede kullanacağımız parametreleri belirliyoruz ve train işlemini başlatıyoruz.
# https://xgboost.readthedocs.io/en/stable/parameter.html#learning-task-parameters
xgb.set_hyperparameters(
eta=0.1,
max_depth=7,
min_child_weight=5,
subsample=0.8,
colsample_bytree=0.8,
objective="binary:logistic",
num_round=150,
)
xgb.fit({'train': s3_input_train,
'validation': s3_input_validation})
# Outputs
# INFO:sagemaker:Creating training-job with name: xgboost-2023-12-24-11-48-15-310
# 2023-12-24 11:48:15 Starting - Starting the training job......
# 2023-12-24 11:48:50 Starting - Preparing the instances for training......
# 2023-12-24 11:49:59 Downloading - Downloading input data...
# 2023-12-24 11:50:29 Downloading - Downloading the training image......
# 2023-12-24 11:51:40 Training - Training image download completed. Training in progress.
# 2023-12-24 11:51:40 Uploading - Uploading generated training modelArguments: train
# [2023-12-24:11:51:33:INFO] Running standalone xgboost training.
# [2023-12-24:11:51:33:INFO] File size need to be processed in the node: 0.05mb. Available memory size in the node: 8536.98mb
# [2023-12-24:11:51:33:INFO] Determined delimiter of CSV input is ','
# [11:51:33] S3DistributionType set as FullyReplicated
# [11:51:33] 940x18 matrix with 16920 entries loaded from /opt/ml/input/data/train?format=csv&label_column=0&delimiter=,
# [2023-12-24:11:51:33:INFO] Determined delimiter of CSV input is ','
# [11:51:33] S3DistributionType set as FullyReplicated
# [11:51:33] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 20 extra nodes, 0 pruned nodes, max_depth=6
# ...
# Training seconds: 112
# Billable seconds: 112
Modelleme işlemi tamamlandıktan sonra modelimizi canlıda (production) kullanabilmek için modelimizi deploy ediyoruz. Modelimizi deploy etmek için deploy fonksiyonunu kullanarak modelimizin çalışacağı instance tipini, instance sayısını ve endpoint adını belirliyoruz.
model_name = "sagemaker-hr-attrition"
xgb_predictor = xgb.deploy(
initial_instance_count=1,
instance_type=instance_type,
model_name=model_name,
endpoint_name=model_name)
Modelimizi deploy ettikten sonra test setini kullanarak modelimizin başarımını ölçüyoruz.
from sagemaker.serializers import CSVSerializer
from sklearn.metrics import confusion_matrix, accuracy_score
xgb_predictor.serializer = CSVSerializer()
predictions = xgb_predictor.predict(x_test.values)
y_pred = np.fromstring(predictions.decode("utf-8"), sep=",")
conf_matrix = confusion_matrix(y_test, y_pred.round())
print(conf_matrix)
print("Accuracy:", round(accuracy_score(y_test, y_pred.round()), 6))
# [241 6]
# [ 28 19]
# Accuracy: 0.884354
Modeli deploy ettiğimiz endpoint üzerinden test etmek istersek de Predictor objesini kullanarak endpoint üzerinden test edebiliriz 👇🏻
from sagemaker.predictor import Predictor
predictor_ep = Predictor(endpoint_name=model_name)
predictor_ep.serializer = CSVSerializer()
predictions_ep = predictor_ep.predict(x_test.values)
y_pred_ep = np.fromstring(predictions_ep.decode("utf-8"), sep=",")
Lambda λ
Modelimizi deploy ettikten sonra aslında modelimize Sagemaker Endpoint’i üzerinden ulaşabiliyoruz. Fakat biraz daha kolaylaştırmak ve bir başka servis ile de entegre etmek adına Lambda ve API Gateway servislerini kullanacağız. Sagemaker üzerinde deploy ettiğimiz modeli Lambda üzerinde kullanabilmek için boto3 ile modelimizi çağıracağız. İlk olarak Author from scratch seçeneği ile Lambda fonksiyonumuzu oluşturuyoruz. Fonksiyonumuza isim verip runtime olarak Python (3.8) seçiyoruz. Halihazırda bir tanımlı bir rolünüz varsa onu seçebilir ya da yeni bir rol oluşturabilirsiniz. Fonksiyonumuz oluştuktan sonra aşağıdaki şekilde lambda_function.py dosyasını oluşturuyoruz. Fonksiyon ayarları içerisinden (Configuration) Environment Variable olarak ENDPOINT_NAME değişkenine Sagemaker üzerinde deploy ettiğimiz modelin endpoint adını giriyoruz.
# lambda_function.py
import os
import boto3
import json
ENDPOINT_NAME = os.environ["ENDPOINT_NAME"]
runtime = boto3.client("runtime.sagemaker")
def lambda_handler(event, context):
data = event.replace("\n", "").replace(" ", "")
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType="text/csv", Body=data)
result = json.loads(response["Body"].read().decode())
pred = int(round(result, 0))
prob = round(result, 2)
return {
'statusCode': 200,
'prediction': json.dumps(pred),
'probabilty': json.dumps(prob)
}
Lambda fonksiyonunu çalıştırırken Access Denied hatası almamak için Lambda fonksiyonunun çalışacağı role inline policy ekleyerek yetki veriyoruz.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource": "endpoint-arn" // isterseniz * ile tüm endpointlere yetki verebilirsiniz
}
]
}
Artık Lambda fonksiyonunu test edebiliriz. Test etmek için aşağıdaki şekilde bir test event’i oluşturuyoruz ve fonksiyonu çalıştırıyoruz ve modelimizin tahminini alıyoruz. Bu örnek için tahmin %8 olasılıkla (çalışanın işten ayrılmayacağı) olarak çıkıyor.
// Input
"1,474,0,3,3,2,1,0,3,1,4,4,1,2061,1,0,0,3"
// Output
{
"statusCode": 200,
"prediction": "0",
"probabilty": "0.08"
}
API Gateway
API Gateway servisini kullanarak Lambda fonksiyonunu Rest API olarak kullanacağız. API GW servisinden daha önce Serverless ile Canlıya Çıkmak yazımda bahsetmiştim. Öncelikle API oluşturmak için Create API butonuna basıyoruz ve API’mize isim vererek API’mizi oluşturuyoruz. API’mizi oluşturduktan sonra API’mize bir endpoint ekliyoruz. Endpoint eklerken method olarak POST işaretliyoruz, Integration Type olarak Lambda Function seçiyoruz ve Lambda fonksiyonumuzu giriyoruz. Stage (dev/prod vs.) ve method (get, post vs.) seçimleri tamamlandıktan sonra API’mizi deploy ediyoruz.
API oluştuktan sonra API’mizi test edebiliriz. Test etmek için API’mizin endpoint’ine bir POST isteği gönderiyoruz.
# test_endpoint.py
import requests
endpoint = "https://uri.execute-api.region-1.amazonaws.com/prod/predict"
data = "1,474,0,3,3,2,1,0,3,1,4,4,1,2061,1,0,0,3"
result = requests.post(endpoint, json=data).json()
result
# {'statusCode': 200, 'prediction': '0', 'probabilty': '0.08'}
Bu yazıda uzun zamandır Türkçe kaynak oluşturmak istediğim Sagemaker’a hızlı bir giriş yapıp model kurduk ve modeli canlıya aldık. Lambda ve API GW kullanarak endpoint’imizi erişilebilir hale getirdik. Bu örnekte Sagemaker’ın sunduğu servislerden sadece birkaçını kullandık ve detaylarına girmedik. 102 yazısında detaylarda görüşmek üzere.
Repo: sagemaker-101
Maliyet 💲: