
MLFlow Auto Logging: AWS S3 ve RDS ile MLFlow
Published:


![]()
Bu yazıda, MLFlow’un Auto Logging özelliğini kullanarak, LightGBM ile model kurup, AWS S3 ve RDS PostgreSQL üzerinde MLFlow kullanarak experiment tracking yapacağız.
Experiment Tracking Nedir?
Experiment Tracking, ilk olarak tekrar edilebilir (reproducible) bir modelleme süreci için gereklidir. Bunun yanında modelin performansını izlemek/kaydetmek ve modelin nasıl geliştirilebileceğini/geliştiğini anlamak için de kullanılabilir. MLFlow bu ihtiyaçları karşılamak için geliştirilmiş açık kaynak (open-source) bir kütüphane. Bu yazının konusu experiment tracking olsa da MLFlow modellerinizi yönetmenize de olanak sağlıyor. MLFlow ile ilgili biraz daha detay isterseniz dokümanına veya daha önce yazdığım fastapi + MLflow + streamlit + AWS = MLOps yazısına göz atabilirsiniz.
MLFLow’u AWS üzerinde kurgulama amacımız merkezi bir takip yapısı oluşturabilmek. Tüm bunlardan bağımsız bir şekilde dilerseniz kendi bilgisayarınızda da MLFlow’u kullanarak, modelinizi takip edebilirsiniz 1. Buradaki amaç farklı kullanıcıların da aynı MLFlow sunucusuna erişebilmesi ve takip yapısını kullanabilmesi. Bu nedenle ilk olarak S3 üzerinde bir bucket oluşturacağız ve sonrasında da RDS üzerinde Free Tier kapsamında bir PostgreSQL veritabanı oluşturacağız.
Experiment Tracking ile ilgili daha fazla bilgi almak isterseniz aşağıdaki kaynaklara göz atabilirsiniz;
- Experiment Tracking - madewithml
- ML Experiment Tracking: What It Is, Why It Matters, and How to Implement It
- Machine Learning Experiment Tracking
- Experiment Tracking - wandb
![]() Kaynak: How to Compare ML Experiment Tracking Tools to Fit Your Data Science Workflow - dagshub
Kaynak: How to Compare ML Experiment Tracking Tools to Fit Your Data Science Workflow - dagshub
AWS S3 ve RDS PostgreSQL
Uygulamanın güvenli olması adına S3’e erişmesi için bir IAM kullanıcısı oluşturup, bu kullanıcıya gerekli izinleri vermemiz gerekiyor. Bu iş için oluşturduğum kullanıcıya sadece ilgili bucket içerisinde FullAccess tanımladım. RDS için erişim bilgilerini doğrudan kod içerisinde tanımlayacağız. Bu yaklaşım geliştirme aşamasında kullanılabilir fakat canlı (production) ortamda güvenlik açısından uygun değildir 2.
RDS kullanarak Free Tier kapsamında bir PostgreSQL veritabanı oluşturacağız. RDS üzerinde veritabanı oluştururken DB Engine olarak PostgreSQL ve geliştirme ortamını Free Tier olarak seçiyoruz ve gerekli ayarları yaparak (DB adı, şifre, security group, vb.) veritabanımızı oluşturuyoruz. DB ayağa kalktıktan sonra erişim için gerekli olan bilgileri not alıyoruz.
Ben Windows üzerinde geliştirme yaptığım için modele ait çıktıların (artifacts) kaydedileceği S3 bucket’ına yazabilmesi için kendi kullanıcım altında environment variable tanımlamaları yaptım (access key, secret key ve region). Windows’ta komut istemci (cmd) kullanarak yapmak isterseniz set komutunu, PowerShell kullanarak yapmak isterseniz $env komutunu kullanabilirsiniz. Unix tabanlı işletim sistemlerinde ise cli üzerinden export komutu ile bu değişkenleri tanımlayabilirsiniz.
Modelleme
Yine, yeniden daha önceki yazılarımda da olduğu gibi IBM HR Analytics Employee Attrition & Performance veri setini kullanarak model kuracağız. Önceki yazılarımda XGBoost 34 ile model kurmama karşın bu sefer LightGBM tercih ettim. Amaç model başarısından çok MLFlow’un nasıl kullanıldığını göstermek olduğu için veri ve modelleme kısmında detaya girmeyeceğiz.
Verinin okunması ve işlenmesi kısımlarını fastapi + MLflow + streamlit + AWS = MLOps yazımda kullandığım fonksiyonlar ile yapacağım ve bu nedenle de çok fazla detaya girmeyeceğim. Aşağıda bulunan run_experiment script’inde modellemeye ait kodları görebilirsiniz. Kısaca bahsetmek gerekirse veri okunuyor, işleniyor, ve MLFlow kullanılarak model kuruluyor. lgb_fit_mlflow fonksiyonuna buradan ulaşabilirsiniz. Fonksiyon içerisinde mlflow.lightgbm.autolog() fonksiyonunu kullanarak LightGBM’in Auto Logging özelliğini aktif hale getiriyoruz. Bu sayede modelin çıktıları (artifacts) otomatik olarak S3 bucket’ına kaydedilecek. Autologging ile varsayılan olarak modele ait metrikler, değişken önemi (feature importance), kullanılan veri seti , modelin kendisi ve modelin hiperparametreleri kaydediliyor. Ek olarak shap kütüphanesinden faydalanarak SHAP değerlerini ve görsellerini (force_plot & summary_plot) de kaydedeceğiz. Bunun yanı sıra log.metric fonksiyonunu kullanarak test, validasyon verilerine ait metrikleri, hata matrisi (confusion matrix) değerlerini (TP, FP, TN, FN) ve matris görselini de kaydediyoruz.
Kod içerisinde Pydantic kullanarak config adında bir class ile modelleme sırasında kullanılacak olan parametreleri, veri setine ait bilgileri ve veritabanına erişmek için gerekli olan bağlantı bilgilerini (connection string) tanımladım. Bu sayede kodun daha okunabilir ve düzenli olmasını amaçladım.
# run_experiment.py
from utils import read_data, preprocessing, data_split, lgb_fit_mlflow
from config import model_settings
# config for the model & data
config = model_settings()
# reading the data
df = read_data(config.data_path, config.selected_features, config.target)
# preprocessing the data
df, labels = preprocessing(df, config.target)
# splitting the data
x_train, x_test, x_val, y_train, y_test, y_val, train_cols, target = data_split(df, config.target)
# fitting the model
model, fi = lgb_fit_mlflow(x_train, x_val, x_test, y_train, y_val, y_test,
config.params, train_cols, config.connection_string, config.artifact_uri)
MLFlow Arayüzü
MLFlow server‘ı başlatmak için aşağıdaki komutu kullanabilirsiniz. Bu sayede MLFlow arayüzünün (mlflow ui) olduğu bir sunucu (localhost’ta) başlatacağız. Normalde kendi lokalimizde çalışıyor olsak çalışmayı yaptığımız dizinde ./mlruns klasörü altında çalışmalarımızı takip edebiliriz. Fakat bu sefer S3 üzerinde bir bucket oluşturduğumuz için, bu bucket’ta bulunan çıktıları takip edebilmek için hem artifacts-destination hem de backend-store-uri parametrelerini tanımlıyoruz. Daha öncesinde AWS profil bilgilerini environment variable olarak tanımladığımız için bu parametrelere ek olarak herhangi bir AWS erişim bilgisi (profil) belirtmemize gerek yok.
mlflow server --default-artifact-root s3://bucket_adi --artifacts-destination s3://bucket_adi --backend-store-uri postgresql://db_user_name:db_pass@db_host:db_port/db_name --serve-artifacts
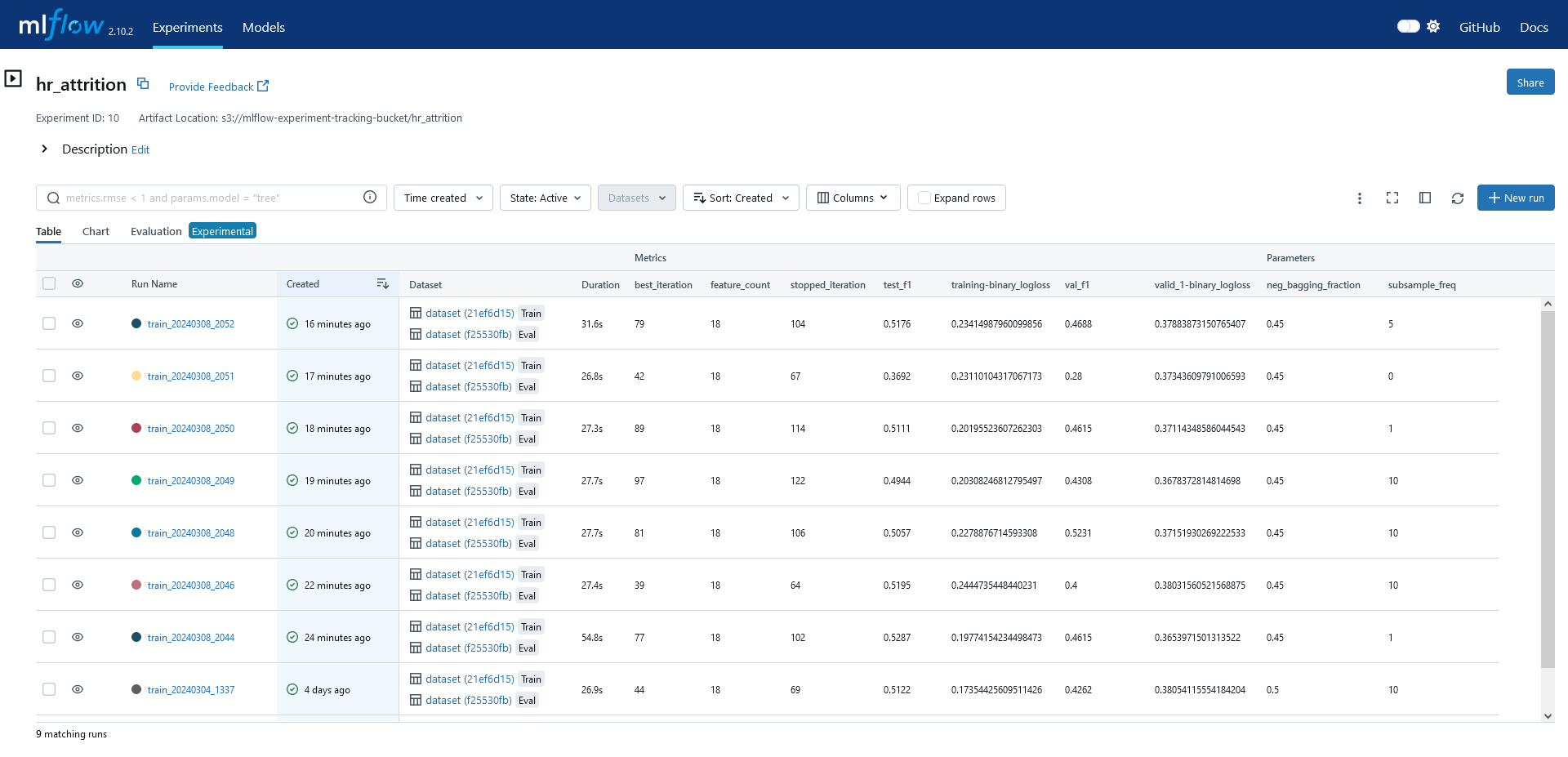
Arayüze ilk kez eriştiğimizte solda experiment isimleri gözükecektir. Bu isimleri tanımlamak için mlflow.set_experiment("experiment_name") fonksiyonunu kullanabilirsiniz. Experiment’i seçtikten sonra ise, ilgili deneme altında tüm çalışmaları görebilirsiniz (Şekil 1A). Bir denemeyi seçtikten sonra (Şekil 1B) Artifacts altında model klasörü, değişken önemleri (json ve görsel halinde) ve kaydettiğimiz diğer dosyalar bulunmaktadır. Datasets sekmesi altında modelleme sırasında kullandığımız veri setine ait değişkenlerin meta verisi tutuluyor (veri kaydedilmiyor). Parameters sekmesinde model için seçilen hiperparametreler ve son olarak Metrics altında da modelleme sırasında/sonrasında kaydedilen metrikler bulunuyor. Şekil 1A 👇🏻
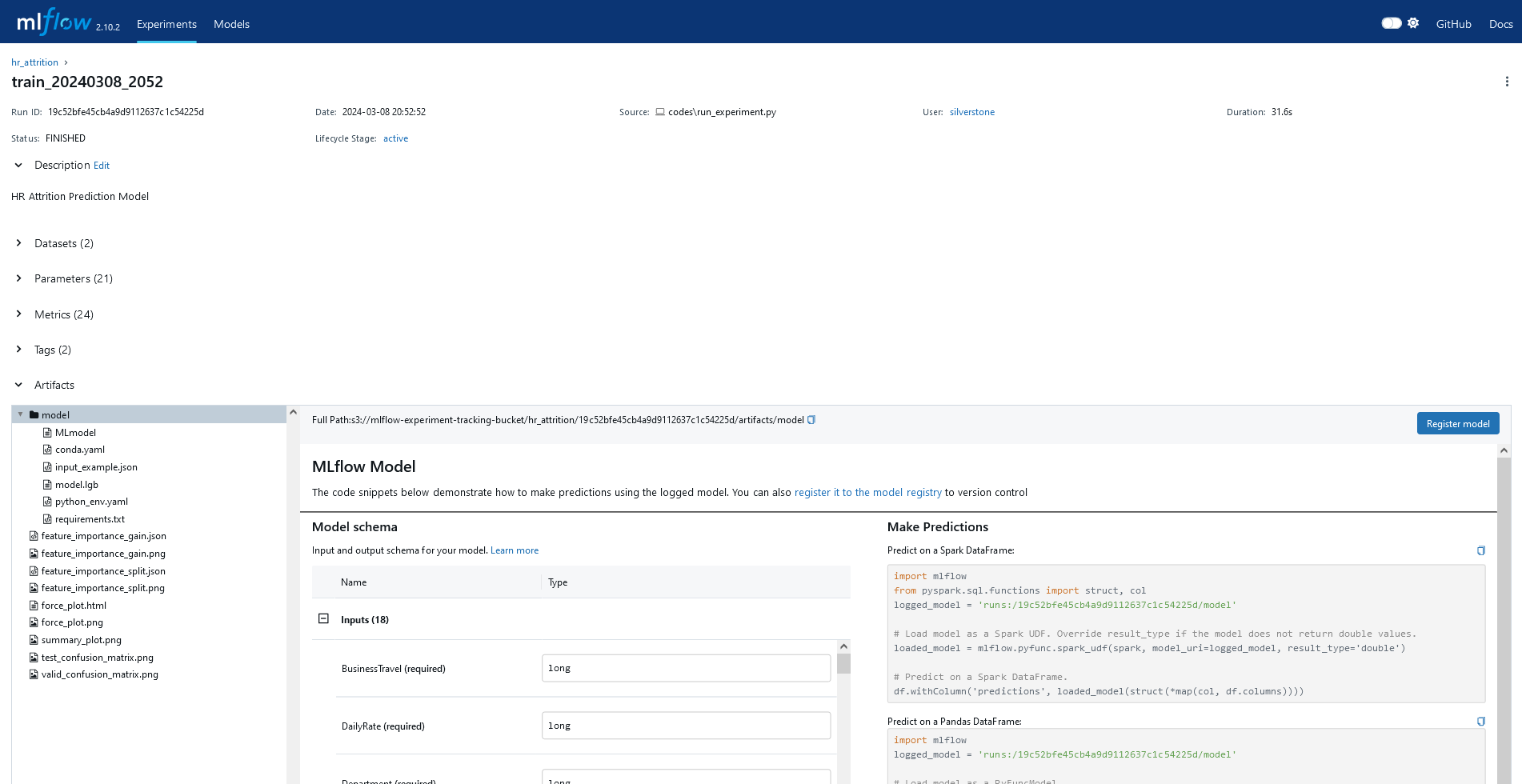
Herhangi bir çalışmayı seçtikten sonra, o çalışmaya ait metrikleri, hiperparametreleri, değişken önemlerini, SHAP değerlerini görebilirsiniz. Şekil 1B 👇🏻
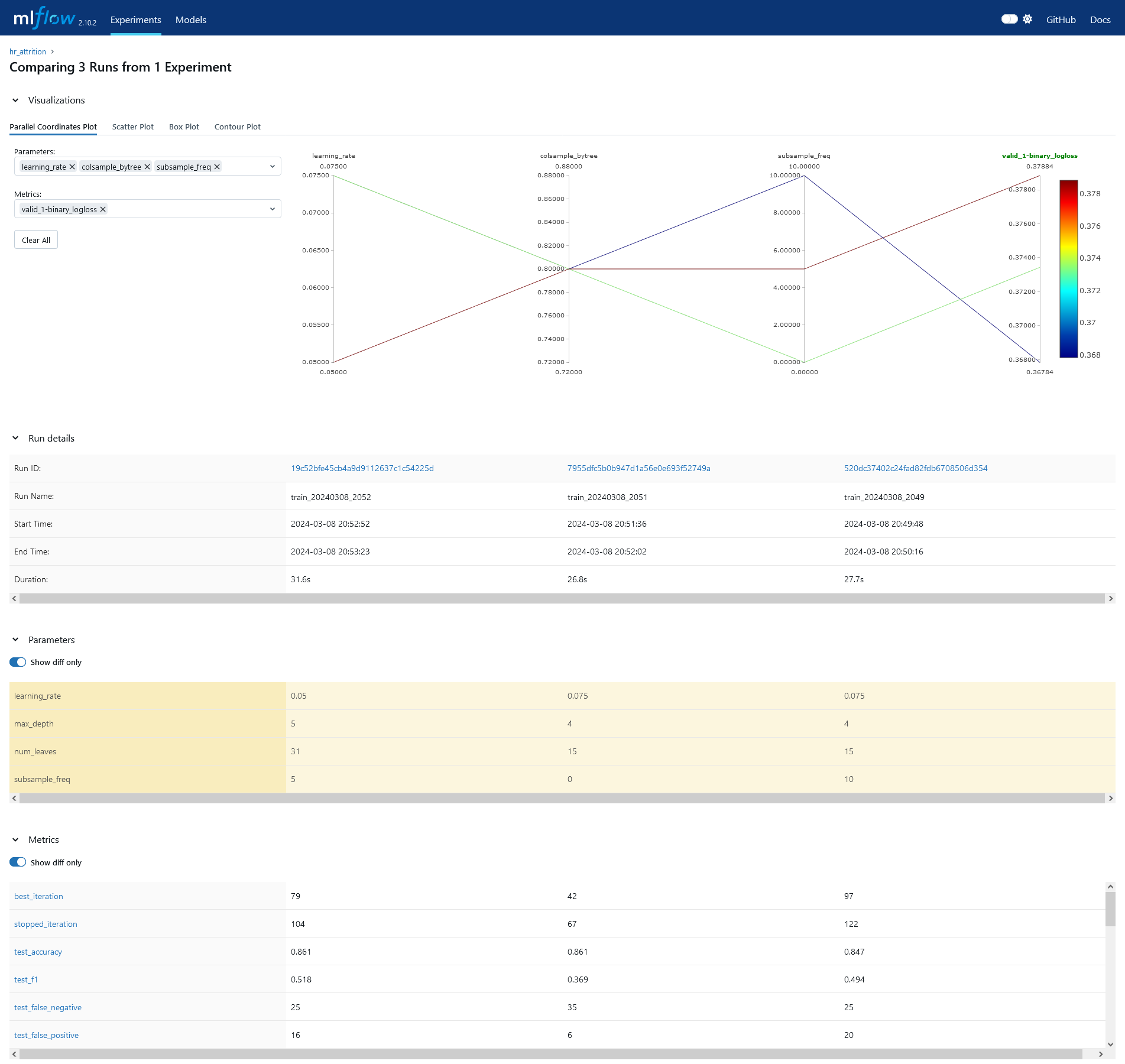
Birden fazla modeli karşılaştırmak isterseniz de modelleri seçip compare butonuna basarak karşılaştırabilirsiniz. Şekil 1C 👇🏻
Tüm bunlara ek olarak dilerseniz kodun çalıştığı ortama ait olan sistem metriklerini psutil paketini kullanarak kaydedebilirsiniz. Ayrıca MLFlow API kullanarak (Python/R/Java), bu verilere erişebilir ve kendi özelleştirmelerinizi yapabilirsiniz. Her ne kadar bu yazıda değinmesem de MLFlow’un Model Registry özelliği ile modelinizi kaydedebilir, versiyonlayabilir ve modelinizi canlıya alabilirsiniz.
MLFlow Auto Logging aslında bir çok kütüphaneyi destekliyor. Her ne kadar benim yazdığım fonksiyon LightGBM için olsa da koddaki lightgbm kısmını kaldırarak ya da başka bir kütüphane ile değiştirerek (örneğin XGBoost) aynı şekilde kullanabilirsiniz. Aslında temel amacım da bu şekilde modüler bir yapı oluşturmak. Değişken çıkarımı (feature extraction), değişken seçimi (feature selection) veya parametre optimizasyonu (hpo) gibi bir çok farklı senaryo için MLFlow’un sunduğu takip yapısını kullanabilirsiniz.
Küçük bir not; mlflow.start_run içerisinde nested = True parametresini kullanarak, fonksiyon içerisindeki bloğun çalıştığı süre boyunca tüm çıktıları aynı run altında toplanmasını sağlayabilirsiniz. Hiperparametre optimizasyonu ya da KFold CV gibi durumlarda bu parametreyi kullanabilirsiniz.
 Kaynak: An End to End Guide to Hyperparameter Optimization using RAPIDS and MLflow on Google's Kubernetes Engine (GKE) - Rapids AI
Kaynak: An End to End Guide to Hyperparameter Optimization using RAPIDS and MLflow on Google's Kubernetes Engine (GKE) - Rapids AI
Repo: MLFlow Auto Logging
Kaynaklar
Kodunuza açık açık connection string, kullanıcı adı, şifre yazmak yerine environment variable veya farklı çözümler kullanarak bu bilgileri saklamanızı öneririm. ↩
Sagemaker-101: Modelleme ve Canlıya Alma (λ ile Serverless) ↩


