
LangChain ile Amazon Bedrock RAG Kullanımı
Published:

Giriş
Bugüne kadar uzak durduğum LLM’lere sonunda bulaşmış bulunmaktayım. Açıkçası her gün yeni bir modelin yeni bir yöntemin çıkması nedeniyle takip etmekte zorlandığım için bir süredir dil modelleri konusunda uzaktan izler durumdaydım. Ancak son zamanlarda Amazon Bedrock üzerindeki modelleri kullanarak metin üretme, özetleme ve semantik arama gibi görevleri gerçekleştirmek için LangChain kütüphanesini kullanmaya başladım. Bu yazıda da LangChain kütüphanesi ve Amazon Bedrock üzerindeki modelleri kullanarak metin üretme ve RAG (Retrieval Augmented Generation) görevini nasıl gerçekleştirebileceğinizi göstereceğim.
Büyük Dil Modelleri (LLM)
LLM’ler (Large Language Models), büyük miktarda veri üzerinde eğitilmiş ve genellikle milyarlarca parametreye sahip olan dil modelleridir. Bu modeller doğal dil işleme (NLP) alanında metin oluşturma, çeviri, metin özetleme, soru-cevap ve dil anlama gibi görevler için sıklıkla kullanılır. LLM’lerin eğitilmesi ve kullanılması genellikle yüksek miktarda hesaplama gücü (ve enerji) ve veri depolama kapasitesi gerektirir. Bu nedenle şu an için geliştirilmesi ve kullanılması oldukça maliyetlidir. Bir diğer konu ise bu modelleri genellikle büyük teknoloji şirketleri ve araştırma kurumlarının geliştirmesi. Bu da sonuç olarak tekelleşmeye ve veri gücüne dayalı rekabet avantajına yol açabilir 1. Bu konuda zaman ne gösterir bilinmez.
LLM’lerin yakın tarihine bakacak olursak 2018’de Google’ın BERT (Bidirectional Encoder Representations from Transformers) modeli (atası 2) ve 2018’de OpenAI’nin GPT (Generative Pre-trained Transformer) modeli bu alanın transformers mimarisi ile öncüleri olmuştur. Arada geçen sürede BERT türevleri (RoBERTa, DistilBERT, DeBERTa) bir hayli kullanılmıştır. 2022 yılında Google’ın PaLM modeli ile LLM teriminin kullanımı 3 oldukça yaygınlaşmıştır. Günümüzde ise GPT-4 (ve benzer diğer modeller) ile LLM’lerin yetenekleri (şu an için) en üst düzeye çıkmıştır ve multi modal (çok modlu) verileri işleyebilir hale gelmiştir.
Retrieval Augmented Generation (RAG)
RAG’lar büyük dil modellerinin doğruluğunu, güncelliğini ve alaka düzeyini artırmak için kullanılan bir tekniktir. LLM’ler metin üretebilirken bazen tamamen rassal bilgiler üretebilir (halüsinasyon) veya belirli bir alandaki en güncel bilgilere sahip olmayabilirler. RAG, bu sınırlamaların etkisini azaltmaya yardımcı olur. Kısaca özetlemek gerekirse RAG, LLM’in kendisine dışarıdan ekstra olarak verilen veriye dayalı bilgi türetmesine yaramaktadır. Bu sayede modele ince ayar (fine-tuning) yapılmasına da gerek kalmaz.
Amazon Bedrock
Bir önceki yazımda Bedrock’ın ne olduğundan kısaca bahsetmiştim. Tekrar hatırlatmak gerekirse Amazon Bedrock, AWS tarafından sağlanan ve üretken yapay zeka uygulamalarının geliştirilmesini ve dağıtımını basitleştiren tam olarak yönetilen bir servistir. AI21 Labs, Anthropic, Cohere, Meta, Stability AI ve Amazon gibi şirketlerinin yüksek performanslı temel modellerine (foundational model) erişim sağlar. API temelli erişimine ek olarak ince ayar (fine-tuning), RAG veya ajan (agent) kullanımı gibi özellikler sunar. Altyapıyı yönetmenize gerek kalmadan, hızlıca prototip oluşturabilir ve uygulamanızı geliştirebilirsiniz.
Bedrock üzerinde Amazon’a ait metin üretme, özetleme, semantik arama, resim üretme modelleri bulunmaktadır. Model listesine buradan ulşabilirsiniz. Bu örnek için embedding’leri oluştururken amazon.titan-embed-text-v2:0 ve metin üretme modeli olarak amazon.titan-text-express-v1 kullanılmıştır. Model detaylarına ise buradan ulaşabilirsiniz.
LangChain
LangChain, büyük dil modelleriyle (LLM’ler) çalışmak ve bunları uygulamalarınıza entegre etmek için kullanabileceğiniz bir framework. Python & JavaScript desteğine sahip ve akla gelen gelmeyen bir çok dil modeli, API ile entegrasyona sahip.
Chroma
Chroma, kendi sitesinde AI-Native açık kaynak vektör veri tabanı olarak tanımlanıyor. Fakat kendisi SQLite tabanlı bir veritabanı ve metin vektörlerini saklamak için kullanılıyor. LangChain’in de bir parçası olarak kullanılıyor.
Uygulama
Daha önce okuduğum makaleler içerisinden seçtiklerim ile bir uygulama yapmaya karar verdim. Uygulama okuduğum makalelerden Amazon Titan Embedding modelini kullanarak metin vektörleri oluşturacak, vektörleri Chroma üzerinde saklayacak ve RAG kullanarak Amazon Titan Express ile metin üretecek. Son olarak bu işlemler bir arayüz aracılığı ile son kullanıcıya sunulacak.
Metin Vektörlerini Oluşturma
Uygulamada ilk olarak Chroma için metin vektörlerini oluşturuyoruz. LangChain altında bulunan PyPDFDirectoryLoader fonksiyonunu kullanarak ilgili PDF’leri yüklüyoruz. Yüklediğimiz PDF’lerden içerikleri çıkartmak için RecursiveCharacterTextSplitter fonksiyonunu kullanıyoruz ve dokümanları parçalar (chunk) haline getiriyoruz.
Chroma DB
Chroma ile vektörleri saklamak (ve aramak) için Chroma‘a class’ını kullanarak çıktı dosyaların kaydedileceği dizini ve embedding’lerin oluşturulacağı fonksiyonu veriyoruz. İşlem sonunda ilgili dizinde db_adi.sqlite ve buna bağlı ilgili vektör dosyaları oluşuyor.
db = Chroma(persist_directory=CHROMA_PATH, embedding_function=get_embedding_function())
Son olarak ise oluşturduğumu parçaları (chunk) db.add_documents kodu ile Chroma veritabanına ekliyoruz.
RAG Sorgusu
Son adımda ise RAG sorgusu için prompt template (istemci şablonu) oluşturuyoruz. Bu şablonu oluştururken ChatPromptTemplate‘i kullanıyoruz. Burada context ve query ile bağlam - soru ilişkisini belirliyoruz. Son olarak oluşturduğumuz şablonu metin üretecek olan modelimize invoke metodu ile gönderiyoruz.
Streamlit Uygulaması
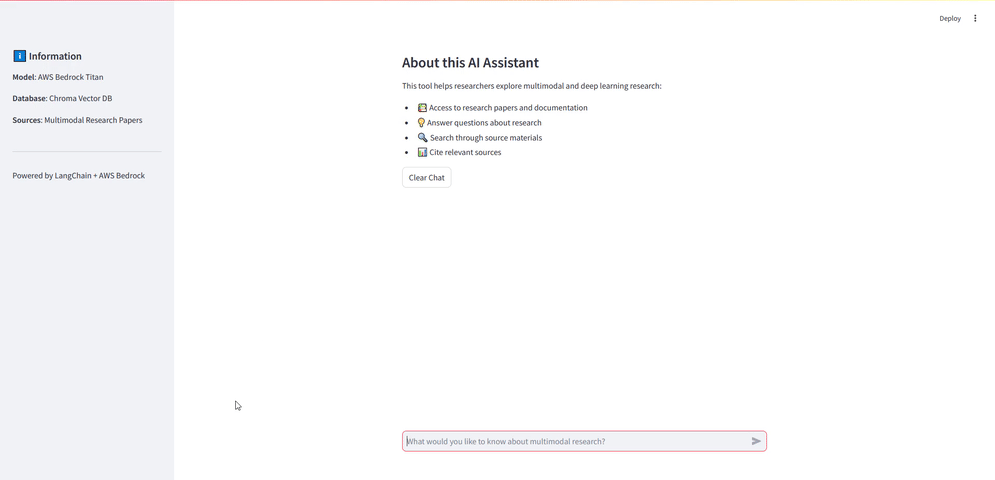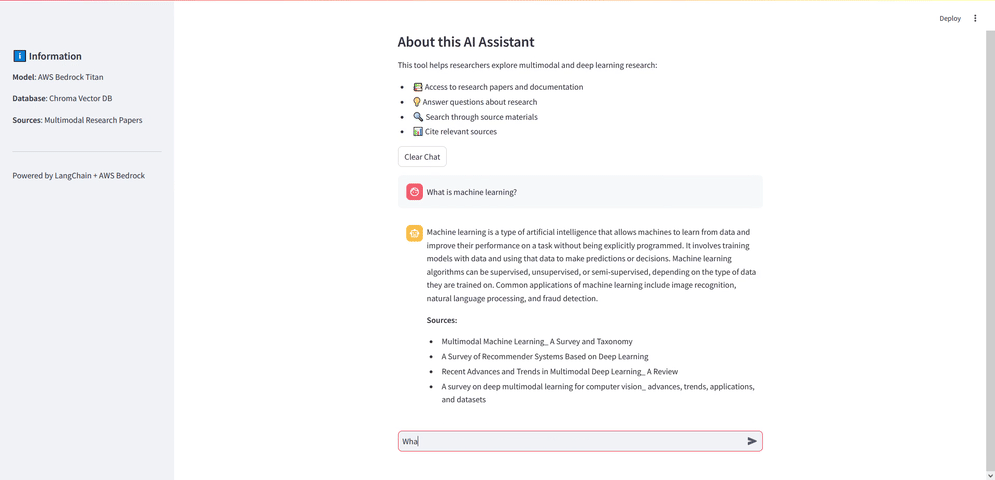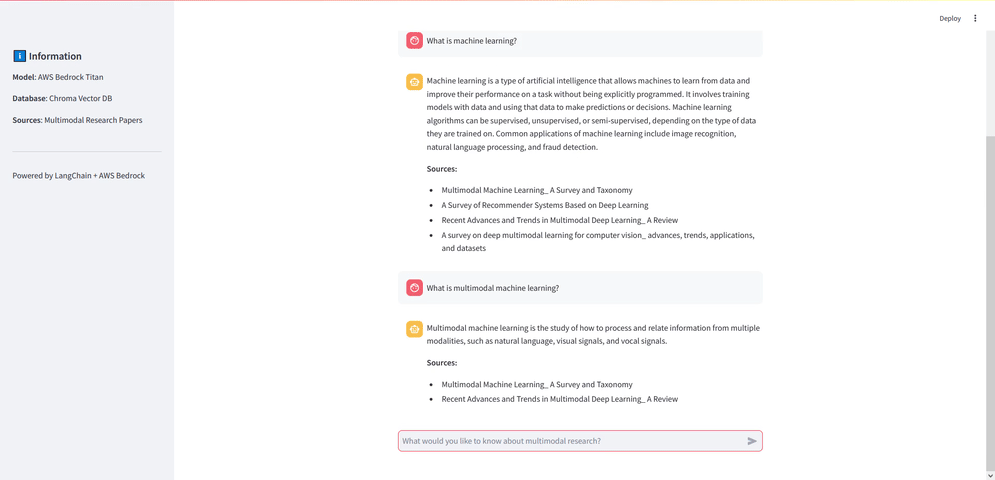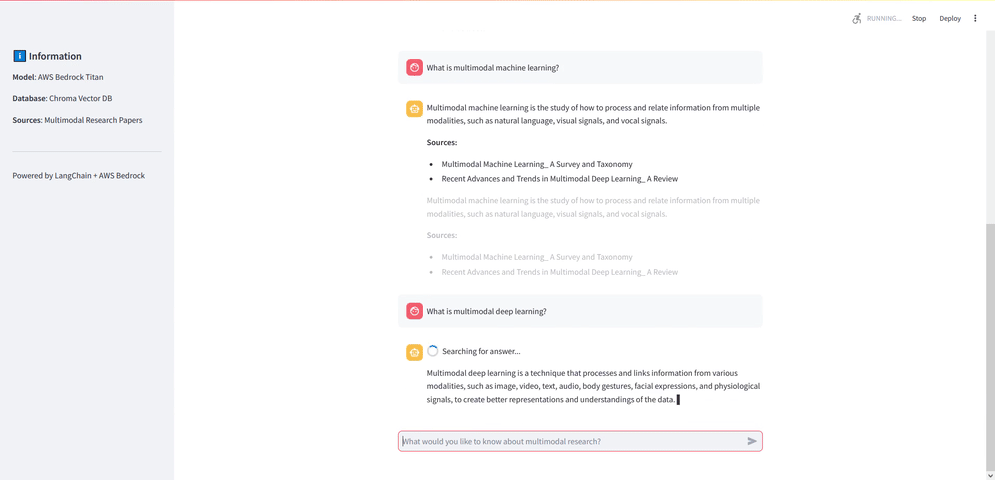
Embedding modeli ile vektörleri oluşturduk, bu vektörleri Chroma ile bir veri tabanında sakladık ve RAG sorgusu için metin üreten modelimizi çağırdık. Son olarak bu işlemleri bir arayüze dökmek için Streamlit kullanıyoruz. Bu arayüz ile bir diyalog kutusu oluşturup kullanıcıdan bir soru alıyoruz ve bu soruyu RAG modeline göndererek sonucu ekrana yazdırıyoruz.
Uygulama için gerekli fonksiyonları (model çağırma, embedding oluşturma, Chroma veritabanına bağlanma gibi) oluşturduktan sonra st.chat_input kullanarak arayüzü oluşturuyoruz ve kullanıcıdan alınan soruyu RAG modeline gönderip sonucu ekrana kullanılan kaynak ile birlikte yazdırıyoruz.
Repo: LangChain ile Amazon Bedrock RAG Kullanımı


