
AWS ile Gerçek Zamanlı Veri İşleme: Kinesis, S3, Lambda ve DuckDB
Published:
![]()
![]()
![]()
Giriş
Daha önce akan veri (stream data) ile ilgili Stream Veriye Giriş: Kafka, Spark ve AWS Glue ile Küçük Veri İşleme başlıklı yazımda Kafka, Spark ve AWS Glue ile veri akışını nasıl işleyebileceğimizi anlatmıştım. Bu yazıda ise AWS Kinesis, S3, DuckDB ve Lambda kullanarak veri akışını nasıl işleyebileceğimizi anlatacağım. Yazının ilk bölümünde AWS Kinesis Data Streams ile veri akışını nasıl oluşturacağımızı ve Lambda ile nasıl işleyebileceğimizi ve S3’e nasıl yazabileceğimizi anlatacağım. İkinci bölümde ise AWS S3 ve DuckDB kullanarak bu verileri nasıl sorgulayabileceğimizi göstereceğim.
AWS Kinesis Data Streams ile Veri Akışı Oluşturma
AWS Kinesis gerçek zamanlı veri akışlarını düşük gecikmeyle (low latency) işlemek, yazmak ve analiz etmek için kullanılan yönetilen bir servistir (managed service). AWS Kinesis ile gerçek zamanlı analizler veya video işleme gibi uygulamalar geliştirmek mümkün. Akan verileri Data Streams ile video’ları ise Video Streams ile işleyebilirsiniz. Daha önce Kinesis servisi altında olan ama artık ayrı bir servis olarak sunulan Kinesis Data Firehose ile de verileri S3, Redshift, Elasticsearch gibi veri saklama servislerine doğrudan gönderebilirsiniz. Data streams gerçek zamanlı veri alımı (data ingestion) için kullanılırken Firehose ise neredeyse gerçek zamanlı (near real-time) veri transferleri için kullanılır. Bunlara ek olarak MSK (Managed Streaming for Apache Kafka) ve Amazon Managed Service for Apache Flink servisleri de kullanılabilir.
Bu yazıda akan veri için Kinesis Data Streams ile veri akışını nasıl oluşturacağımızı ve Lambda ile nasıl işleyip S3’e yazabileceğimizi anlatacağım. Kinesis Data Streams verileri shard’lar (parçalar) halinde işler. Her shard belirli bir miktarda veri ve işlem kapasitesine sahiptir. Shard sayısını artırarak veri işleme kapasitesini artırabilirsiniz. Konsoldan stream oluşturmak için 👇🏻
- Kinesis servisine gidin ve “Data Streams” sekmesine tıklayın.
- “Create data stream” dedikten sonra Stream adını girin ve capacity mode olarak “Provisioned” seçeneğini seçin.
- Provisioned shard sayısını belirleyin (1 yeterli).
- “Create data stream” butonuna tıklayarak stream’i oluşturun.
CLI ile yapmak isterseniz de 👇🏻
aws kinesis create-stream --stream-name data-stream-name --shard-count 1
Bu arada Data Stream’e gelen veriler Lambda ile işlenecek ve S3’e yazılacak. Bunun için de S3’te bir bucket oluşturmanız gerekiyor. Konsolda S3’e gidin ve “Create bucket” butonuna tıklayın. Bucket adını girin ve diğer ayarları yaparak bucket’ı oluşturun.
CLI ile yapmak isterseniz de 👇🏻
aws s3api create-bucket --bucket bucket-anem --region region-name
AWS Lambda ile Veri Akışını İşleme
AWS Lambda’dan daha önce AWS Lambda-101, Sagemaker 101, R ile Scraping - İkinci El Araç Verisi ve Serverless ile Canlıya Çıkmak yazılarımda bahsetmiştim. AWS Solutions Architect Assoicate sınavında da Kinesis ve Lambda entegrasyonu soru olarak bir hayli karşılaşılan bir senaryo. Özellikle Kinesis Data Streams ve Data Firehose farklı tam olarak da Lambda kullanımında ortaya çıkıyor. Firehose doğrudan S3’e yazabilirken Data Streams için Lambda kullanmanız gerekiyor. Lambda ile Kinesis Data Streams’i entegre etmek için aşağıdaki adımları izleyebilirsiniz:
- Konsolda Lambda’ya gidin ve “Create function” butonuna tıklayın.
- “Author from scratch” seçeneğini seçin ve fonksiyon adını girin.
- Runtime olarak Python 3.x seçin.
- “Create function” butonuna tıklayarak fonksiyonu oluşturun.
Çıkan ekranda Code Source kısmına aşağıda bulunan kodu yapıştırın ve Deploy ile kodu deploy edin. Bu kod ile Kinesis Data Streams’den gelen veriler S3’te seçili bucker içinde processed_data klasörü altına yazılacaktır.
import base64
import boto3
import json
import uuid
from datetime import datetime
s3_client = boto3.client('s3')
bucket_name = 'bucket-name' # S3 bucket adınızı buraya girin
def lambda_handler(event, context):
for record in event['Records']:
payload = base64.b64decode(record['kinesis']['data']).decode('utf-8')
processed_data = {
'id': str(uuid.uuid4()),
'timestamp': datetime.utcnow().isoformat(),
'data': payload
}
object_key = f"processed_data/{processed_data['id']}.json"
s3_client.put_object(
Bucket=bucket_name,
Key=object_key,
Body=json.dumps(processed_data)
)
print(f"Uploaded to S3: s3://{bucket_name}/{object_key}")
return {
'statusCode': 200,
'body': json.dumps('Processing complete.')
}
Lambda fonksiyonunu oluşturduktan sonra Kinesis Data Streams ile Lambda fonksiyonunu entegre etmeniz gerekiyor. Bunun için:
- Lambda fonksiyonunun sayfasında “Configuration” sekmesine gidin.
- “Triggers” bölümüne gidin ve “Add trigger” butonuna tıklayın.
- “Kinesis” seçeneğini seçin ve oluşturduğunuz Kinesis Data Stream’i seçin.
- “Batch size” olarak 1000 seçeneğini seçin ve “Add” butonuna tıklayın. Bu adımları tamamladıktan sonra Kinesis Data Streams’den gelen veriler Lambda fonksiyonu tarafından işlenecek ve S3’e yazılacaktır.
Kinesis Data Streams’e Veri Gönderme
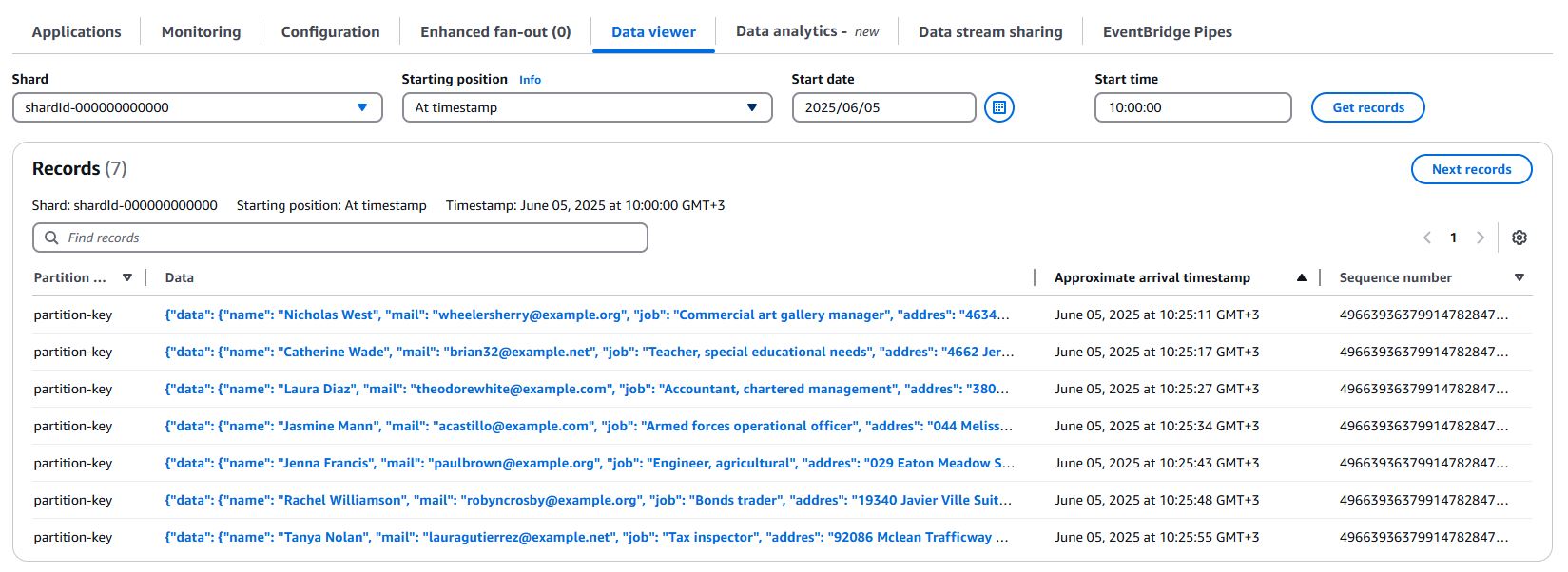
Kinesis Data Streams’e veri göndermek için daha önce stream-101 yazımda kullandığım kod parçacığını kullanacağım. Aşağıdaki kodu create-kinesis-stream.py dosyasına kaydedin ve çalıştırın. for döngüsü olduğu için 100 kayıt için çalışacak. Kod çalıştığı süre boyunca faker ile rastgele veriler üretecek ve Kinesis Data Streams’e gönderecektir. Bu veriler Lambda fonksiyonu tarafından işlenecek ve S3’e yazılacaktır. Veri gönderdikçe S3’te processed_data klasörü altında JSON dosyaları oluşacaktır. Dilerseniz Data Stream altında Data Viewer ile de verileri görebilirsiniz.
import boto3
import json
from faker import Faker
import random
import time
fake = Faker()
def generate_data():
data = {
"name": fake.name(),
"mail": fake.email(),
"job": fake.job(),
"addres": fake.address().replace("\n", " "),
"country": fake.country(),
"age": random.randint(18, 80),
"salary": random.randint(1000, 10000),
"register_date": fake.date(),
}
return data
session = boto3.Session(profile_name="profile_name")
kinesis_client = session.client("kinesis", region_name="region_name")
stream_name = "stream_name"
i = 0
for i in range(100):
data = {"data": generate_data()}
kinesis_client.put_record(StreamName=stream_name, Data=json.dumps(data), PartitionKey="partition-key")
time.sleep(random.randint(1, 10))
i += 1
S3 ve DuckDB ile Veri Sorgulama
create-kinesis-stream.py script’ini çalıştırıp Lambda ile S3’e veri yazdıktan sonra S3’teki verileri sorgulamak için DuckDB kullanacağız. DuckDB, açık kaynak , analitik sorguları destekleyen SQL tabanlı bir veritabanı. Kendim de CSV, JSON ve Parquet formatındaki verileri işlemek için sıklıkla DuckDB kullanıyorum. Bu yazıda Athena kullanımına alternatif olarak veriyi lokalde sorgulamak için DuckDB kullanacağız. Aşağıdaki adımları izleyerek S3’te bulunan JSON formatındaki verileri DuckDB ile sorgulayabilirsiniz:
import duckdb
# connection oluşturup gerekli eklentileri yükleme
conn = duckdb.connect()
conn.query(
"""
install aws; -- https://duckdb.org/docs/stable/core_extensions/aws
load aws;
install httpfs; -- https://duckdb.org/docs/stable/core_extensions/httpfs/overview
load httpfs;
"""
)
# S3'teki verileri sorgulamak için gerekli ayarları yapma
conn.query("""
CALL load_aws_credentials(); -- https://duckdb.org/docs/stable/core_extensions/aws#legacy-features
create secret secret_name (
type s3,
key_id 'aws_access_key_id',
secret 'aws_secret_access_key',
region 'aws_region'
);
"""
)
Lokalde çalışacağı için ilk sorguda gerekli eklentileri yükleyecek ve çalıştıracak. Sonraki sorguda ise AWS eklentisi ile S3 bağlantısını oluşturacak. Herhangi bir hata almamanız durumunda aşağıdaki çıktıyı alacaksınız. Alabileceğiniz hata mesajı ise AWS Secret bilgilerinizi doğru girilmemesinden kaynaklanıyor olabilir (DuckDB S3 Parquet Import). Bu durumda aws_access_key_id, aws_secret_access_key ve aws_region bilgilerini kontrol edin. Bununla birlikte IAM kullanıcısının S3’e erişim izni olduğundan emin olun.
┌─────────┐
│ Success │
│ boolean │
├─────────┤
│ true │
└─────────┘
Oluşturduğunuz secret’ı görmek isterseniz conn.query("from duckdb_secrets();") olur da silmek istersseniz ise conn.query("drop secret if exists secret_name;")
Burada basit bir ETL mantığı ile processed_data klasörü altındaki tüm verileri sorgulayacağım ve hepsini birleştirip tek bir parquet dosyasına yazacağım. Bu nedenle de attach ile conn.query("""attach 'ducklake:metadata.ducklake' (data_path 's3://bucket-name/processed_data/'); """) ilgili dosyayı oluşturmak için S3 dizinini belirtiyorum.
JSON formatındaki verimiz aşağıdaki 👇🏻
{"id": "3bf429d7-3f6d-4cf3-856a-24afe1544dad", "timestamp": "2025-06-05T07:32:44.173986", "data": "{"data": {"name": "Larry Arnold", "mail": "simschelsey@example.org", "job": "Community development worker", "addres": "954 Emily Locks Perryborough, MS 80256", "country": "Northern Mariana Islands", "age": 18, "salary": 1053, "register_date": "2013-10-08"}}"}
S3’e veriyi yazarken ID ve timestamp bilgileri eklediğimiz ve data kısmında nested JSON verisi olduğundan bunu sorgulanabilir hale getirmek için json_extract fonksiyonunu kullanacağım. ID, timestamp ve data kısmındaki JSON verisini ayrı sütunlara ayırmak için aşağıdaki gibi bir tablo oluşturacağız. Bu tabloyu metadata.kinesis olarak adlandırdım. DuckDB’de tablo oluşturmak için CREATE TABLE sorgusunu kullanabilirsiniz.
conn.query(
"""create table if not exists metadata.kinesis (
id varchar,
timestamp timestamp,
name string,
mail string,
job string,
address string,
country string,
age int,
salary float,
register_date date
)"""
)
Tabloyu oluşturduktan sonra S3’te bulunan verileri doğrudan bu tabloya yazarak tüm JSON verilerini tek bir tabloya dönüştürüp parquet formatında saklayacağız.
conn.query(
"""
insert into metadata.kinesis
select
id,
timestamp,
json_extract_string(data, '$.data.name') AS name,
json_extract_string(data, '$.data.mail') AS mail,
json_extract_string(data, '$.data.job') AS job,
json_extract_string(data, '$.data.addres') AS address,
json_extract_string(data, '$.data.country') AS country,
CAST(json_extract_string(data, '$.data.age') AS INTEGER) AS age,
CAST(json_extract_string(data, '$.data.salary') AS INTEGER) AS salary,
json_extract_string(data, '$.data.register_date') AS register_date
FROM read_json('s3://bucket-name/processed_data/*.json')
"""
)
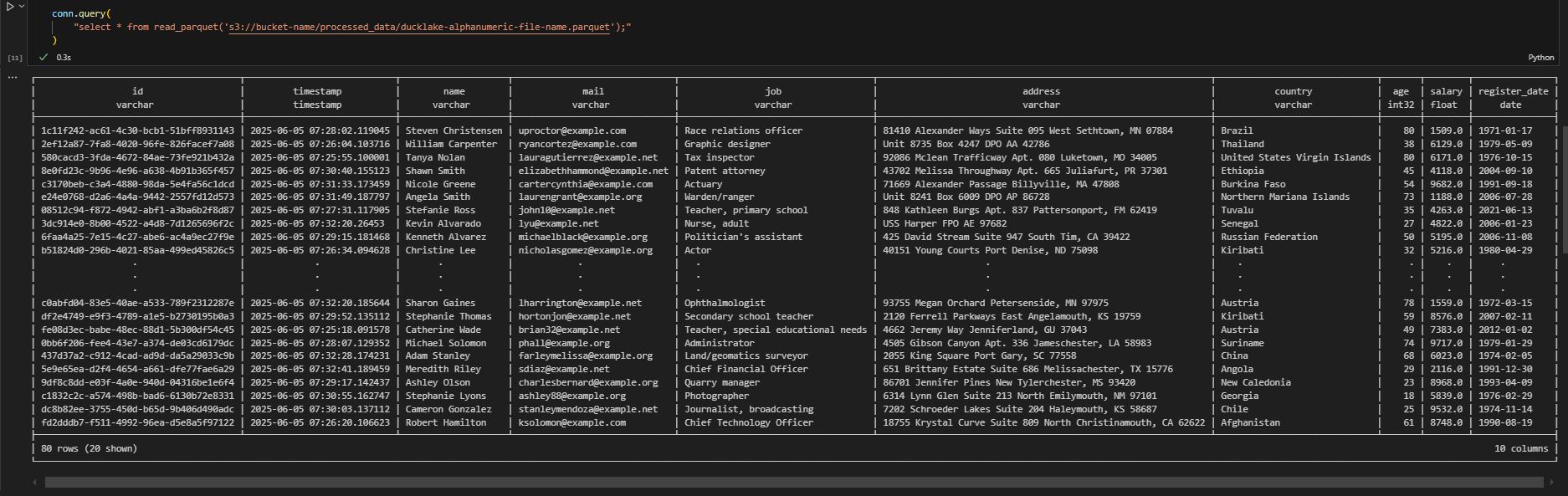
Bu aşamadan sonra veriler metadata.kinesis tablosuna ve parquet formatında S3’e yazılacaktır. Tablodan sorgulamak isterseniz conn.query("select * from metadata.kinesis limit 5;") S3’ten parquet ile sorgulamak isterseniz de conn.query("select * from read_parquet('s3://bucket-name/processed_data/ducklake-alphanumeric-file-name.parquet');")
Sonuç
Bu yazıda AWS Kinesis Data Streams, S3, DuckDB ve Lambda kullanarak veri akışını nasıl oluşturacağımızı, Lambda ile nasıl işleyebileceğimizi ve S3’e nasıl yazabileceğimizi anlattım. Ayrıca S3’teki verileri DuckDB ile nasıl sorgulayabileceğimizi gösterdim. Bu yöntemle gerçek zamanlı veri akışlarını işleyebilir ve S3’teki verileri SQL tabanlı sorgularla analiz edebilirsiniz. Bununla birlikte Athena kullanımına gerek kalmadan verileri lokalde sorguladık. Bu örnek için oluşturduğum JSON verilerin her biri 300 byte civarında olduğu ve sayısı az (80) olduğundan küçük ölçekli bir örnek oldu. Ancak gerçek hayat uygulamalarında veri boyutu veya sayısı çok daha fazla olacağından lokalde sorgulamak yerine S3 üzerinde Athena ile sorgulamak daha uygulanabilir olacaktır. Yine bu örnekte Kafka yerine Kinesis Data Streams kullandık. Ancak Kafka ile de benzer şekilde veri akışını işleyebilirsiniz.
Not: Lambda ve S3’ten veri okumak için IAM üzerinden gerekli izinleri vermeniz gerekiyor. Lambda fonksiyonuna S3’e yazma izni ve S3 bucket’ına Lambda fonksiyonundan erişim izni vermeniz gerekiyor. Ayrıca Kinesis Data Streams’e de Lambda fonksiyonunun erişim izni olması gerekiyor. Bu izinleri IAM rolü üzerinden verebilirsiniz. AWS S3 ve DuckDB kullanarak S3’teki verileri sorgulamak için de Amazon Secret ve Access Key’e ihtiyacınız olacak. Bu bilgileri AWS IAM üzerinden alabilirsiniz.
# requirements.txt
boto3==1.38.3
duckdb==1.30.0
faker==37.3.0
Script’lere github.com/silverstone1903/stream-102 üzerinden erişebilirsiniz.


