Uygulamalı Analitik: dbt, DuckDB ve Streamlit
Published:
![]()
![]()
![]()
Bu uygulamada (uzun süre sonra ilk defa AWS olmadan hem de) dbt ve DuckDB kullanarak veri modelleme pratiği yapacağız. Senaryo ham verinin DuckDB’ye yüklenmesi, dbt ile veri modellerinin oluşturulması ve son olarak Streamlit ile basit bir dashboard hazırlanmasını içerecek. Veri seti olarak Kaggle’da bulunan Blinkit Marketing and Customer Feedback Dashboard veri setini kullanacağız.
İlk olarak dbt ve DuckDB’nin ne olduğunu ve neden birlikte kullanıldıklarını açıklayarak başlayalım.
dbt ve DuckDB Nedir?
Modern veri projelerindeki ana problemlerden biri veriyi toplamak değil toplanan veriyi doğru, tutarlı, test edilebilir ve tekrar üretilebilir hale getirmektir. Bu noktada dbt (data build tool) ve DuckDB öğrenmesi kolay olmalarına rağmen birlikte kullanıldıklarında oldukça güçlü bir yapı sunuyor.
dbt veritabanı içinde çalışan SQL tabanlı bir veri dönüşüm (data build tool) aracıdır. dbt’nin temel yaklaşımı ham verinin zaten veritabanında bulunduğu ve dönüşümlerin Python script’leriyle başka bir ortamda değil doğrudan SQL ile veritabanı içinde yapılması gerektiği fikrine dayanır. dbt ile SQL dosyaları üzerinden katmanlı veri modelleri oluşturulur ve bu veri modelleri arasındaki bağımlılıklar/ilişkiler otomatik olarak yönetilir. Bununla birlikte verinin belirli kurallara uyup uymadığını kontrol eden testler yazılabilir. Aynı zamanda dbt model ve kolon seviyesinde dokümantasyon üretmeye imkan tanır ve tüm bu süreci Git gibi versiyon kontrol sistemleriyle birlikte çalışacak şekilde kurgular. Bu yönüyle dbt analitik SQL yazımını daha disiplinli, okunabilir ve sürdürülebilir hale getirir.
DuckDB ise analitik sorgular için tasarlanmış gömülü (embedded) bir veritabanıdır. SQLite’a benzer şekilde tek bir dosya üzerinden çalışır ancak temel farkı, OLAP tipi analitik iş yükleri için optimize edilmiş olmasıdır. Kurulum gerektirmemesi, oldukça hızlı çalışması ve CSV ya da Parquet gibi dosyaları doğrudan sorgulayabilmesi DuckDB’yi özellikle veri analizi ve prototipleme süreçlerinde öne çıkarır. Python, R veya komut satırı gibi farklı ortamlara kolayca entegre edilebilmesi de data scientist’lar için önemli bir avantajdır. Pratikte DuckDB büyük ve karmaşık bir veri ambarı kurmadan, yerel bir makinede analitik SQL çalıştırabilme imkanı sunar.
dbt ve DuckDB birlikte kullanıldığında ise ortaya hafif (light-weight) ama veri katmanları için oldukça etkili bir geliştirme ortamı çıkar. dbt veri modelleme, test etme ve dokümantasyon gibi veri modeli tarafını üstlenirken DuckDB bu modelleri çalıştıran hızlı ve kurulumu zahmetsiz bir analitik motor (analytical engine) görevi görür. Bu kombinasyon özellikle küçük ve orta ölçekli analitik projelerde son derece pratiktir.
Uygulama Adımları
Verinin DuckDB’ye Yüklenmesi
Uygulamada örnek veri olarak Kaggle’da bulunan Blinkit Marketing and Customer Feedback Dashboard veri setini kullanacağız. Ham veriyi CSV olarak basit bir Python script’i ile DuckDB’ye yükleyip dbt ile veri modellerimizi oluşturacağız.
import duckdb
import pandas as pd
from pathlib import Path
ROOT = Path(__file__).resolve().parent.parent
DATA_DIR = ROOT / "data"
DB_PATH = ROOT / "blinkit.duckdb"
con = duckdb.connect(DB_PATH.resolve())
con.execute("CREATE SCHEMA IF NOT EXISTS raw")
files = {
"customer_feedback": "blinkit_customer_feedback.csv",
"marketing_performance": "blinkit_marketing_performance.csv",
"orders": "blinkit_orders.csv",
"order_items": "blinkit_order_items.csv",
"products": "blinkit_products.csv",
"customers": "blinkit_customers.csv",
}
for table, file in files.items():
df = pd.read_csv(DATA_DIR.resolve() / file)
con.execute(
f"""
CREATE OR REPLACE TABLE raw.{table} AS
SELECT * FROM df
"""
)
con.close()
Yukarıdaki Python script’i ile data klasöründeki CSV dosyalarını DuckDB veritabanına raw şeması altında yükledik. Veri yapısını Raw, Staging ve Mart (data mart) olarak üç katmana ayıracağız. Raw katmanı ham veriyi içerirken Staging katmanı veri temizleme ve standartlaştırma işlemlerinin yapıldığı ara katmandır. Mart katmanı ise analiz ve raporlama için optimize edilmiş son veri modellerini içerir. dbt’nin bu konudaki tavsiye edilen pratiklerine uyarak ilerleyeceğiz. Bununla birlikte kurguyu Star Schema modeline göre yapacağız. Tabloları fact ve dimension olarak ayıracağız. models/mart altındaki sql dosyları fct ve dim, raw veriden dönüşütürülen veriye ait SQL’ler ise stg ön ekleri ile isimlendirilecektir.
dbt Projesinin Oluşturulması
dbt’yi ilk çalıştırmada Error: Invalid value for '--profiles-dir' hatası aldım. Bunun için sırasıyla komut satırında (command prompt / cli) aşağıdaki komutları çalıştırıp profiles.yml dosyasını oluşturuyoruz:
# windows için
mkdir %USERPROFILE%\.dbt
notepad %USERPROFILE%\.dbt\profiles.yml
profiles.yml dosyasını aşağıdaki gibi dolduruyoruz:
blinkit:
target: dev
outputs:
dev:
type: duckdb
path: blinkit.duckdb
Sonrasında projenin olduğu klasörde ise dbt_project.yml dosyasını açıp aşağıdaki gibi dolduruyoruz:
name: 'blinkit_dbt_project'
profile: 'blinkit'
model-paths: ["models"]
models:
blinkit:
staging:
+materialized: view
marts:
+materialized: table
profiles.yml dosyasındaki path parametresi ile DuckDB veritabanı dosyasının yolunu belirtiyoruz. dbt_project.yml dosyasında ise projenin adını, kullanılacak profili ve modellerin bulunduğu klasörleri tanımlıyoruz. Ayrıca staging modellerinin view, mart modellerinin ise table olarak materialize edilmesini sağlıyoruz. profiles.yml dbt için farklı kaynaklardaki verileri yönetmeye yarayan profil ayarlarıyken dbt_project.yml dosyası ise projenin kendine özgü ayarlarını içerir ve her bir proje için tanımlanması gerekir.
dbt Modellerinin Oluşturulması ve Test Edilmesi
bunları oluşturduktan sonra models/staging ve models/marts klasörleri altına sql dosyalarını ekliyoruz. Staging modelleri için stg_orders.sql, stg_products.sql, stg_customers.sql, stg_feedback.sql ve stg_marketing_performance.sql ve stg_order_items.sql dosyalarını oluşturuyoruz. Buradaki amacımız raw şeması altında oluşan tablolardaki kolon isimlerini standartlaştırmak, gereksiz kolonları ayıklamak ve veri temizleme işlemlerini tek bir yerde toplamaktır. Örnek bir staging modeli aşağıdaki gibi 👇🏻
SELECT
order_id,
product_id,
quantity,
unit_price,
quantity * unit_price AS total_price -- Örnek olarak eklediğimiz hesaplanmış bir kolon
FROM {{ source('raw', 'order_items') }}
-- raw şemasındaki order_items tablosunu kaynak olarak kullanıyoruz ve notasyon olarak dbt'nin source fonksiyonunu kullanıyoruz
Stagging klasörü altında schema.yml ile kaynak tabloların tanımlarını yapıyoruz. Örnek bir source tanımı aşağıdaki gibi 👇🏻
version: 2
sources:
- name: raw
description: "Blinkit Raw data source"
tables:
- name: customer_feedback
description: "Customer feedback data"
- name: marketing_performance
description: "Marketing performance data"
- name: orders
description: "Orders data"
- name: order_items
description: "Order items data"
- name: products
description: "Products data"
- name: customers
description: "Customers data"
Mart modelleri için ise dim_customers.sql, dim_products.sql, fct_orders.sql, fct_customer_orders.sql, fct_delivery_feedback.sql, fct_marketing_order_feedback.sql, fct_marketing.sql, fct_order_items.sql, fct_orders.sql fct_rfm_roi.sql, ve fct_rfm.sql dosyalarını oluşturuyoruz. Temel olarak ROI, RFM ve basit analizler için sorguları oluşturuyoruz. Marts için buradan, staging modelleri için ise buradan erişebilirsiniz.
Bunlara ek olarak marts klasörü altında schema.yml ile test ve dokümantasyon tanımlarını yapıyoruz. Örnek bir test tanımı aşağıdaki gibi 👇🏻
models:
- name: fct_orders
description: "Order fact table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null
- unique
- name: customer_id
description: "Customer ID associated with the order"
- name: order_total
description: "Order total amount"
Bu tanım ile fct_orders modelindeki order_id kolonunun null olmaması ve tekil (unique) olması gerektiğini belirtiyoruz. Bu tür testler veri kalitesini sağlamak için önemli.
Tüm modelleri oluşturduktan sonra dbt komutları ile modelleri çalıştırabiliriz. İlk olarak dbt run komutunu ile modelleri oluşturuyoruz. Olası bir hata durumunda ise tüm tabloları drop edip baştan oluşturmak için dilerseniz dbt clean komutunu dilerseniz de dbt run --full-refresh komutunu kullanabilirsiniz. Kontrol amaçlı veya başka bir nedenle tek bir modeli çalıştırmak isterseniz de dbt run --models model_adi komutunu kullanabilirsiniz. Örneğin: dbt run --models stg_customers.
dbt run ile modelleri çalıştırdıktan sonra dbt test komutu ile tanımladığımız testleri çalıştırabiliriz. Bu komut tüm modellerdeki testleri çalıştırır ve sonuçları raporlar. Hata durumunda hangi testin başarısız olduğunu ve nedenini gösterir.
dbt arkaplanda proje klasörü içerisinde target klasörünü oluşturur ve bu klasör altında run_results.json ile manifest.json dosyalarını yaratır. run_results.json dosyası çalıştırılan modellerin sonuçlarını manifest.json dosyası ise dbt projesinin metadata bilgilerini içerir. Bu dosyalar dbt’nin çalıştırma geçmişini ve proje yapısını takip etmesine yardımcı olur.
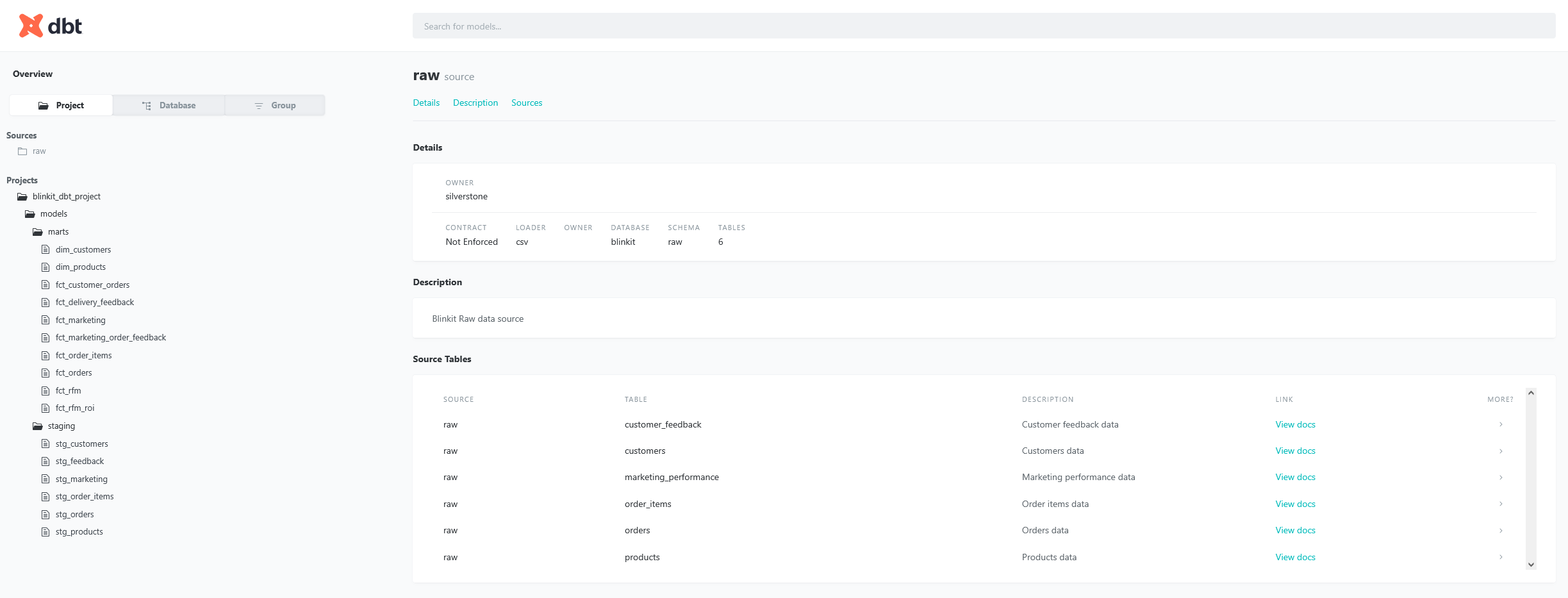
dbt docs generate komutu ile dokümantasyon oluşturabilir, dbt docs serve komutu ile de bu dokümantasyonu görüntüleyebilirsiniz. Bu dokümasyon, modellerinizin yapısını, ilişkilerini ve açıklamalarını içeren interaktif bir web arayüzü sağlar. Bu arayüzde kodun hem orijinal halini hem de derlenmiş halini görebilirsiniz. Aşağıdaki görsellerde dokümantasyonun nasıl göründüğünü görebilirsiniz
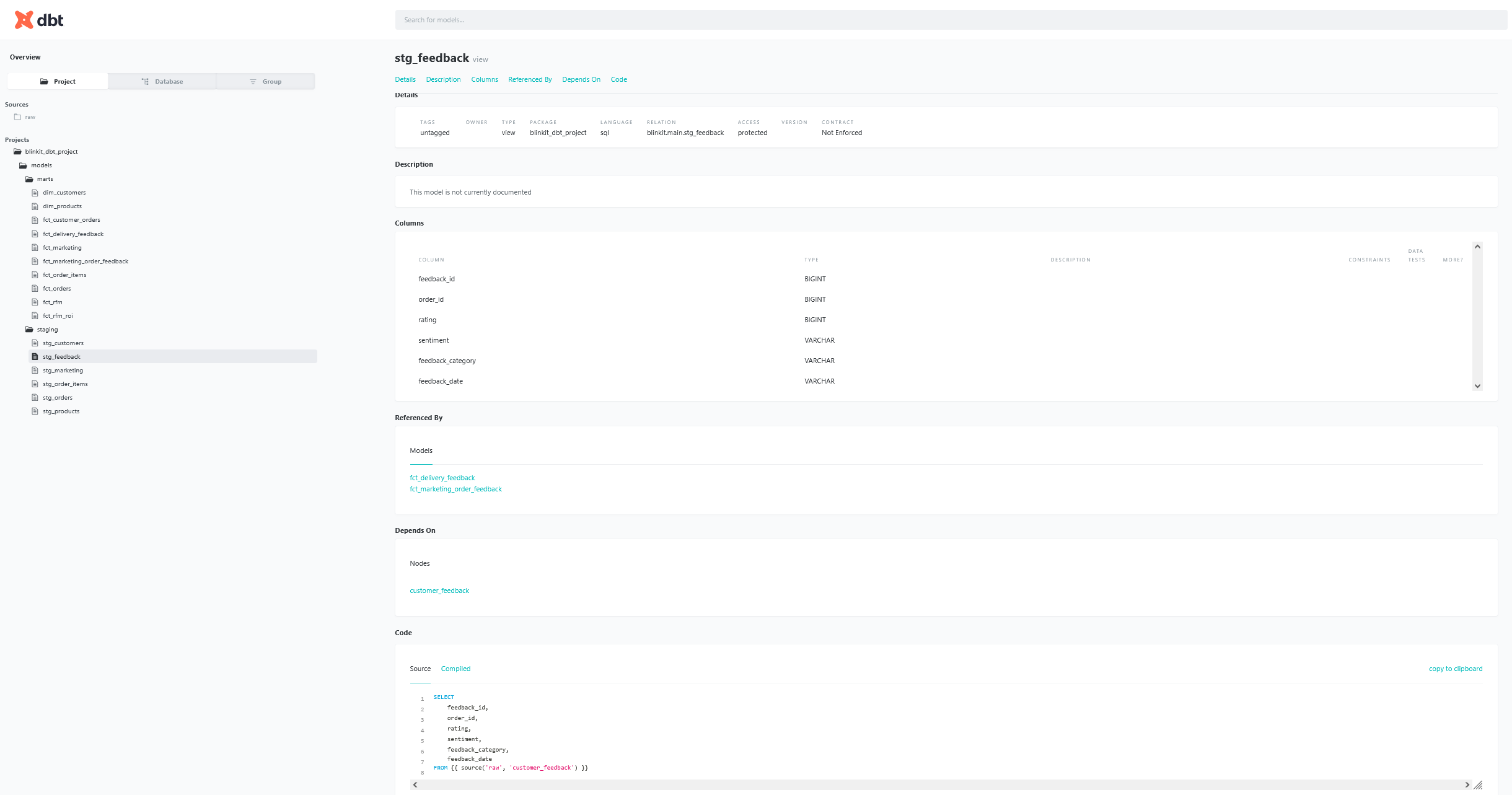
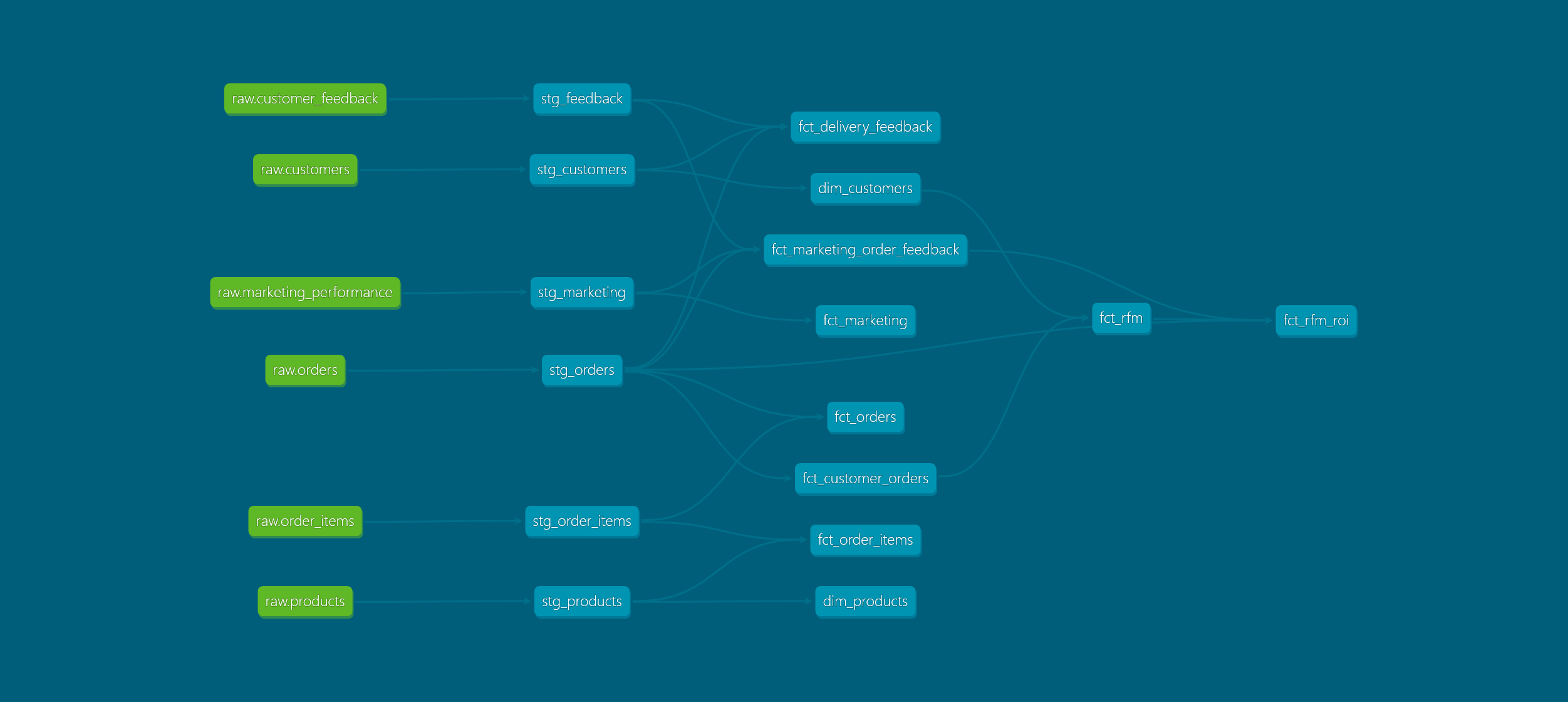
Son olarak oluşturduğumuz modelin lineage (akış) bilgisini de dokümantasyon arayüzünde görüntüleyebiliriz. Bu özellik ile bir modelin hangi kaynaklardan ve diğer modellerden türetildiğini görsel olarak inceleyebiliriz. Aşağıdaki görselde lineage görünümünü görebilirsiniz.
Streamlit ile Basit Bir Dashboard Oluşturulması
Son adımda ise dbt ile oluşturduğumuz veri modellerini kullanarak Streamlit ile basit bir dashboard hazırlayacağız. Basitçe DuckDB’ye bağlanıp bazı temel metrikleri ve görselleştirmeleri yapabiliriz. Streamlit içerisinde yer alan yapının temel kod yapısı aşağıdaki gibi 👇🏻
# app.py
# src/utils.py
def get_connection(db_path: str = "blinkit.duckdb"):
return duckdb.connect(db_path, read_only=True)
con = get_connection()
# src/queries.py
def kpi_delivery():
return """
SELECT
COUNT(DISTINCT order_id) AS total_orders,
SUM(is_delayed) AS delayed_orders,
ROUND(AVG(rating), 2) AS avg_rating
FROM fct_delivery_feedback
"""
kpi_df = con.execute(q.kpi_delivery()).df()
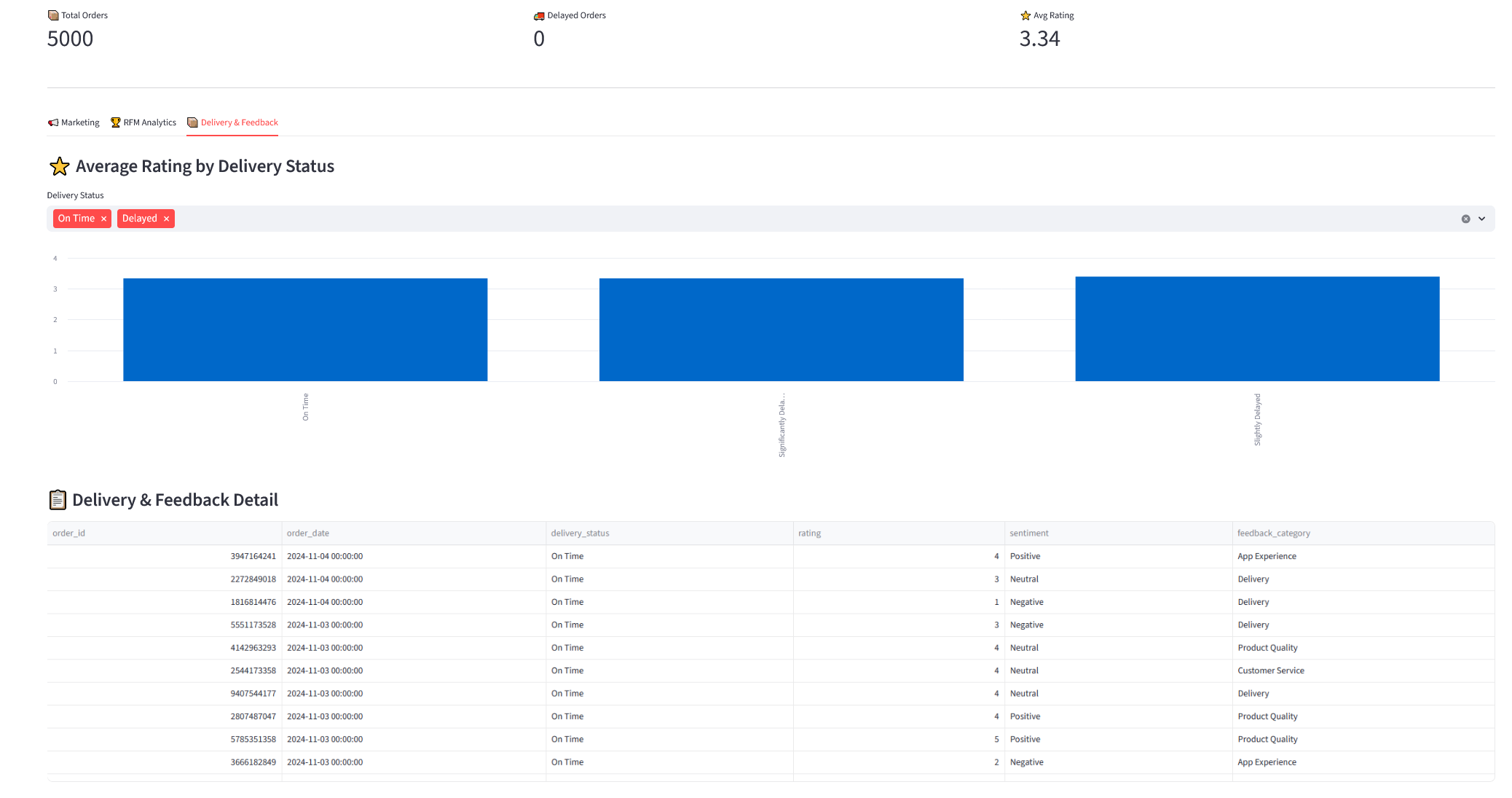
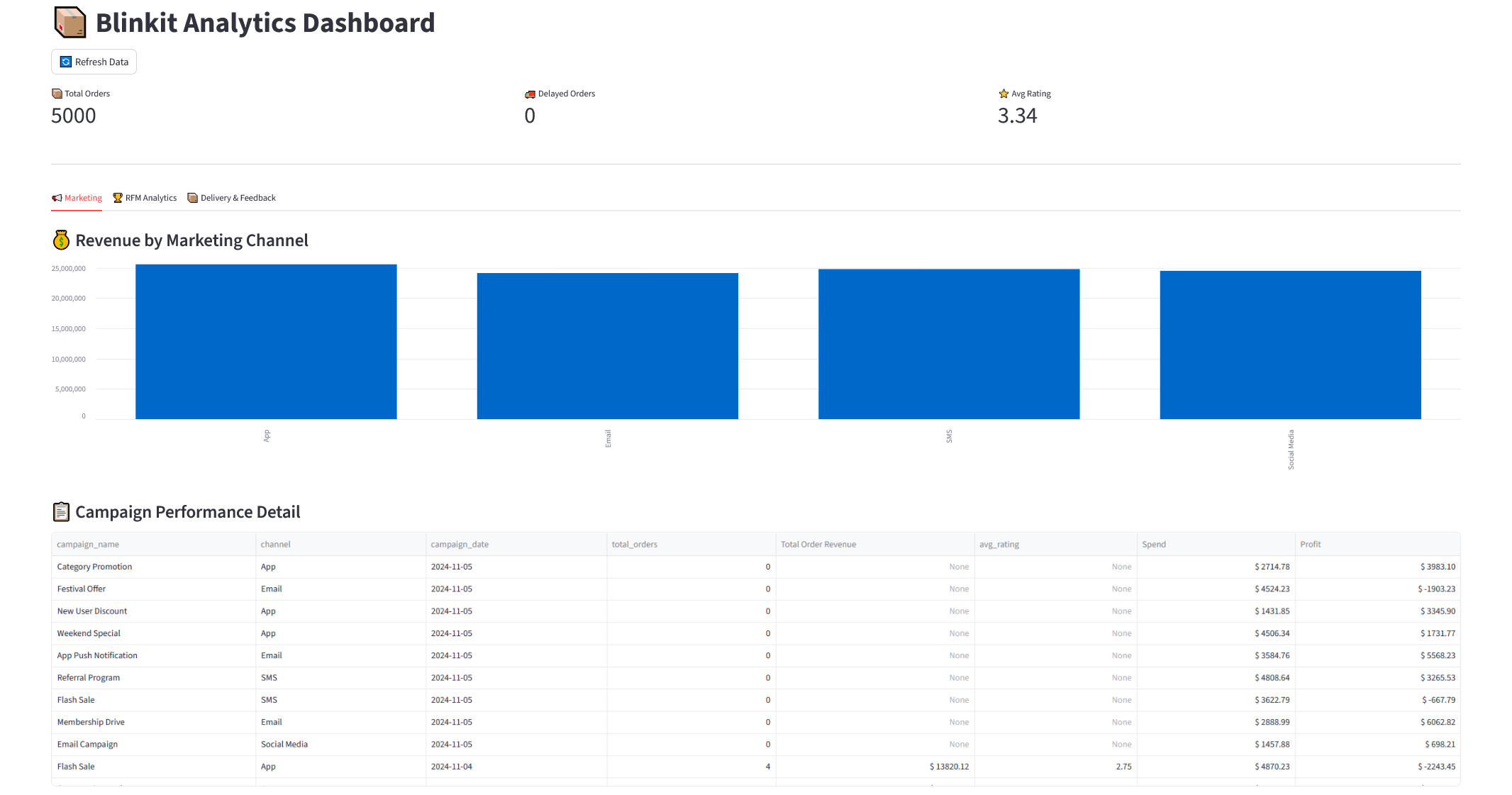
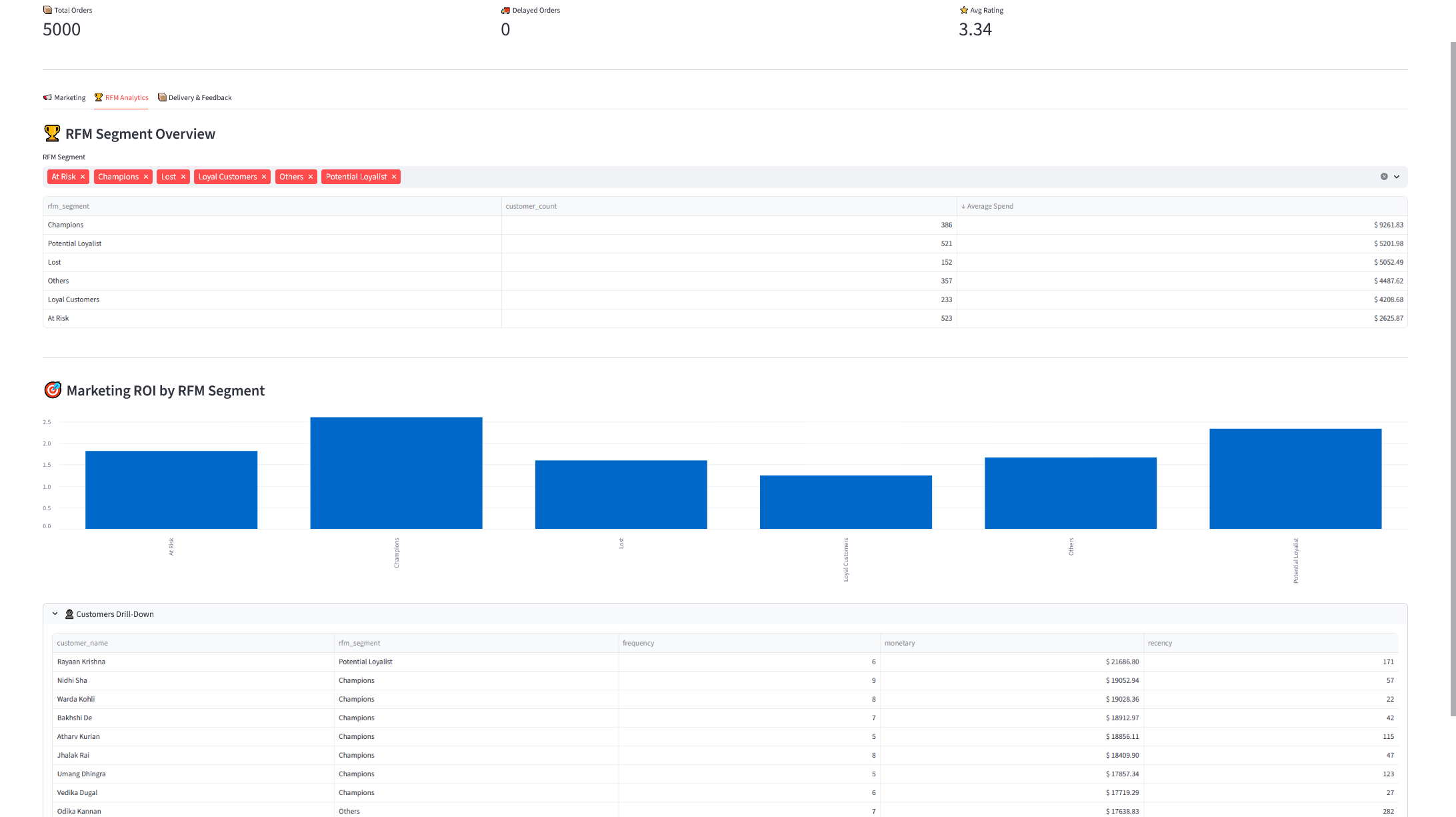
Uygulama kodlarının tamamına GitHub repo‘sundan ulaşabilirsiniz. Aşağıda dashboard’a ait ekran görüntülerini bulabilirsiniz 👇🏻