
Serverless Veri Akışı: DuckDB, Lambda ve Apache Iceberg ile NYC Taksi Verisi
Published:
![]()
![]()
![]()
![]()
Bu yazıda DuckDB, AWS Lambda ve Apache Iceberg kullanarak uçtan uca bir veri akışı (data pipeline) oluşturacağız. Veri seti olarak New York City Taxi & Limousine Commission’ın (NYC TLC) Yellow Taxi Trip Record parquet formatındaki açık verilerini kullanıyoruz. Buradaki amacımız serverless bir ortamda (Lambda) DuckDB’nin S3 üzerinden doğrudan veri okuma/yazma ve SQL ile dönüşüm yapma yeteneklerini kullanarak ETL işlemlerini gerçekleştirmek. PyIceberg ile Glue Data Catalog entegrasyonu sayesinde de sonuçları Iceberg formatında saklayarak Athena ile sorgulanabilir hale getireceğiz.
Daha önce DuckDB’yi Stream-102 ve dbt ile DuckDB yazılarımda kullanmıştım. Bu sefer ise DuckDB’yi Lambda üzerinde çalıştırarak serverless bir ETL pipeline’ı kuracağız.
Akış 3 aşamadan meydana geliyor:
┌──────────────────────────────────────────────────────────────────────────┐
│ AWS Lambda (Container Image) │
│ DuckDB + PyIceberg + PyArrow │
│ │
│ ┌──────────┐ ┌──────────────┐ ┌────────────────┐ │
│ │ Ingest │ ──→ │ Preprocess │ ──→ │ Analytics │ │
│ │ │ │ │ │ │ │
│ │ NYC TLC │ │ DuckDB SQL │ │ DuckDB SQL │ │
│ │ Parquet │ │ → PyArrow │ │ → PyArrow │ │
│ │ → S3 Raw │ │ → Iceberg │ │ → 4x Iceberg │ │
│ └──────────┘ └──────────────┘ └────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────┘
│ │ │
▼ ▼ ▼
┌──────────┐ ┌─────────────────┐ ┌─────────────────┐
│ S3 Bucket│ │ AWS Glue Data │ │ Amazon Athena │
│ raw/ │ │ Catalog │ │ (SQL Queries) │
│ iceberg/ │ │ (nyc_tlc DB) │ │ │
└──────────┘ └─────────────────┘ └─────────────────┘
Tüm aşamalar tek bir Lambda fonksiyonu üzerinde çalışıyor. Lambda container image olarak deploy ediliyor ve SAM (Serverless Application Model) ile yönetiliyor. İlk aşamada NYC TLC’nin CloudFront endpoint’inden parquet dosyaları S3’e indiriliyor. İkinci aşamada DuckDB SQL ile veri temizleme ve dönüşüm işlemleri yapılıyor, sonuç Iceberg formatında S3’e yazılıyor. Son aşamada ise işlenmiş tablo üzerinden çeşitli özet (aggregation) sorguları çalıştırılarak analiz sonuçları ayrı Iceberg tablolarına yazılıyor. Tüm tablolar Glue Data Catalog’da nyc_tlc database’i altında kayıtlı oluyor ve Athena ile sorgulanabiliyor.
Tüm bunları yaparkenki kısıtlar ise aşağıdaki gibi:
- Tek S3 bucket’ı: Tüm veriler tek bir bucket içerisinde klasör (
rawveiceberg) olarak ayrılıyor (ideal olan ayrı bucket’lar kullanmak). - Lambda timeout: Ingest, Preprocess ve Analytics için Lambda fonksiyonu maksimum 15 dakika (900 saniye) çalışabilir.
- Lambda Memory: 4096 MB. DuckDB in-memory çalıştığı için yüksek memory ihtiyacı var.
- Container image: DuckDB extension’ları (httpfs, aws) build aşamasında önceden yükleniyor. Çünkü Lambda runtime’ında internete çıkış olmayabilir.
Uygulama
Uygulama üç ana bileşenden oluşuyor: Dockerfile, SAM template ve Lambda handler. Ben kodları çalıştırmak için Cloud9 ortamını kullanıyorum, ancak kendi lokalinizde Docker, AWS SAM CLI, ve AWS CLI yüklüyse de aynı şekilde çalıştırabilirsiniz.
Dockerfile
Lambda fonksiyonumuz container image olarak çalıştığı için Dockerfile’ı oluşturuyoruz ilk olarak. Dockerfile’da dikkat edilmesi gereken nokta ise DuckDB extension’larının (httpfs, aws) imaj oluşturulurken yüklenmesi. Lambda runtime’ında internete çıkış olmayabileceği için extension’ları önceden yüklüyoruz.
# Dockerfile
FROM public.ecr.aws/lambda/python:3.12
RUN dnf install -y gcc gcc-c++ && dnf clean all
COPY requirements.txt ${LAMBDA_TASK_ROOT}/
RUN pip install --no-cache-dir -r ${LAMBDA_TASK_ROOT}/requirements.txt
# DuckDB extension'larını yükleme
RUN python -c "import duckdb; con = duckdb.connect(); con.execute('INSTALL httpfs'); con.execute('INSTALL aws'); con.close()"
# PyIceberg kontrolü
# RUN python -c "from pyiceberg.catalog.glue import GlueCatalog; print('PyIceberg OK')"
COPY src/ ${LAMBDA_TASK_ROOT}/
CMD ["handler.lambda_handler"]
SAM Şablonu
SAM (Serverless Application Model) Lambda fonksiyonları, API Gateway, DynamoDB tabloları gibi serverless kaynakları tanımlamak ve deploy etmek için kullanılan bir framework. Basit bir yaml syntax’i ile altyapıyı kod olarak tanımlamamızı sağlıyor. Bu örnekte de SAM kullanarak Lambda fonksiyonumuzu, S3 bucket’ımızı ve gerekli IAM izinlerini tanımlıyoruz. Lambda fonksiyonuna hem S3 hem de Glue Data Catalog erişimi veriyoruz. Iceberg’in Glue ile çalışabilmesi için glue:CreateTable, glue:UpdateTable, glue:DeleteTable izinlerini de tanımlıyoruz.
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: DuckDB Lambda - NYC TLC Trip Record Data Pipeline.
Parameters:
BucketNameParam:
Type: String
Default: nyc-tlc-duckdb-pipeline
Resources:
DataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref BucketNameParam
VersioningConfiguration: # S3 bucket'ında versiyonlama açarak veri kaybı riskini azaltıyoruz
Status: Enabled
DuckDBPipelineFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: duckdb-nyc-tlc-pipeline
PackageType: Image # image veya zip olabilir, biz image kullanıyoruz
Architectures: [x86_64]
MemorySize: 4096 # Lambda için bellek sınırı (4 GB)
Timeout: 900 # Lambda için timeout sınırı (15 dakika)
Environment:
Variables:
BUCKET_NAME: !Ref DataBucket
GLUE_DATABASE: nyc_tlc
Policies:
- S3CrudPolicy:
BucketName: !Ref DataBucket
- Statement:
- Effect: Allow
Action:
- glue:GetDatabase
- glue:CreateDatabase
- glue:GetTable
- glue:CreateTable
- glue:UpdateTable
- glue:DeleteTable
- glue:GetTables
- glue:BatchCreatePartition
- glue:GetPartitions
- glue:BatchGetPartition
- glue:UpdatePartition
- glue:DeletePartition
Resource:
- !Sub "arn:aws:glue:${AWS::Region}:${AWS::AccountId}:catalog"
- !Sub "arn:aws:glue:${AWS::Region}:${AWS::AccountId}:database/nyc_tlc"
- !Sub "arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/nyc_tlc/*"
Metadata:
Dockerfile: Dockerfile
DockerContext: .
Şablonun infrastructure composer ile görselleştirilmiş hali ise aşağıdaki gibi 👇🏻
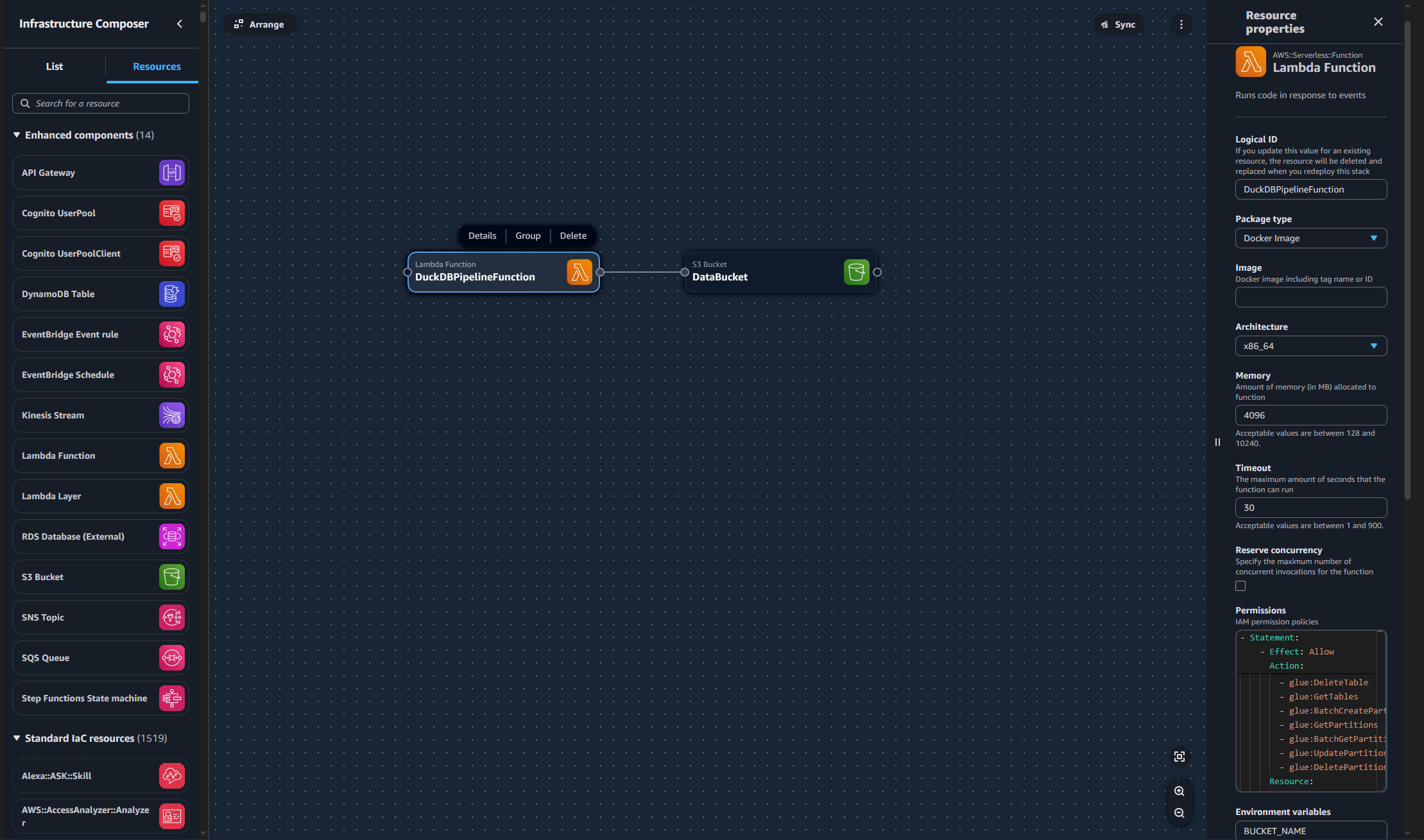
DuckDB
Lambda ortamında DuckDB’yi başlatırken dikkat edilmesi gereken bir husus var; Lambda’da HOME environment variable’ı tanımlı değil. Bu nedenle DuckDB’nin extension’ları yükleyebilmesi için home_directory ayarını /tmp olarak belirtmemiz gerekiyor. Bu olmadan IOException: Can't find the home directory hatası alıyorsunuz.
Aşağıdaki fonksiyon DuckDB bağlantısını başlatır, gerekli extension’ları yükler ve AWS credential’larını ayarlar.
def _init_duckdb() -> duckdb.DuckDBPyConnection:
con = duckdb.connect(":memory:")
con.execute("SET home_directory = '/tmp';")
con.execute("INSTALL httpfs; LOAD httpfs;")
con.execute("INSTALL aws; LOAD aws;")
# Lambda'nın IAM role credential'larını kullanıyoruz
aws_region = os.environ.get("AWS_REGION", "eu-central-1")
aws_access_key = os.environ.get("AWS_ACCESS_KEY_ID", "")
aws_secret_key = os.environ.get("AWS_SECRET_ACCESS_KEY", "")
aws_session_token = os.environ.get("AWS_SESSION_TOKEN", "")
con.execute(f"SET s3_region = '{aws_region}';")
if aws_access_key:
con.execute(f"SET s3_access_key_id = '{aws_access_key}';")
con.execute(f"SET s3_secret_access_key = '{aws_secret_key}';")
if aws_session_token:
con.execute(f"SET s3_session_token = '{aws_session_token}';")
return con
Iceberg Catalog
Glue’nun veri kataloğunu Iceberg’ten faydalanarak oluşturuyoruz. Warehouse olarak S3 bucket’ımızın iceberg/ prefix’ini belirtiyoruz. _init_iceberg_catalog fonksiyonu Glue’da nyc_tlc namespace’ini (database) arar ve yoksa oluşturur.
def _init_iceberg_catalog() -> GlueCatalog:
catalog = GlueCatalog(
name="glue",
**{
"s3.region": os.environ.get("AWS_REGION", "eu-central-1"),
"warehouse": f"s3://{BUCKET_NAME}/iceberg",
},
)
try:
catalog.load_namespace_properties(GLUE_DATABASE)
except NoSuchNamespaceError:
catalog.create_namespace(GLUE_DATABASE)
return catalog
Pipeline #1 | Ingest
İlk aşamada NYC TLC’nin halka açık adresinden parquet dosyaları indirilerek S3’teki raw/yellow/ prefix’ine yazılıyor. Burada DuckDB’nin COPY komutu ile doğrudan URL’den veriyi okuyup S3’e yazma yeteneğini kullanıyoruz. Herhangi bir dönüşüm yapılmıyor, veri olduğu gibi kopyalanıyor. Burada dikkat edilmesi gereken nokta yıl ve ay bilgisini kullanarak veri indiriyoruz. Toplu veri indirmek için lambda fonksiyonuna year ve months parametreleri veriliyor.
def stage_ingest(con, year, months):
for month in months:
src_url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_{year}-{month:02d}.parquet"
dest = f"s3://{BUCKET_NAME}/raw/yellow/yellow_tripdata_{year}-{month:02d}.parquet"
con.execute(f"""
COPY (SELECT * FROM read_parquet('{src_url}'))
TO '{dest}' (FORMAT PARQUET, COMPRESSION ZSTD);
""")
Pipeline #2 | Preprocess
Bu aşamada ham veri DuckDB SQL ile temizlenip dönüştürülüyor ve sonuç PyArrow tablosu olarak Iceberg formatında S3’e yazılıyor.
Uygulanan dönüşümler:
- Null pickup/dropoff timestamp’lı satırlar filtreleniyor
trip_distance <= 0vefare_amount <= 0satırlar çıkarılıyor- Kolon isimleri standartlaştırılıyor (
VendorID->vendor_id,PULocationID->pickup_location_idvb.) - Yeni kolonlar ekleniyor:
pickup_date,pickup_hour,pickup_dow,trip_duration_min - Location ID’ler INT’e cast ediliyor
arrow_table = con.execute(f"""
SELECT
CAST(VendorID AS INT) AS vendor_id,
tpep_pickup_datetime,
tpep_dropoff_datetime,
passenger_count,
trip_distance,
CAST(PULocationID AS INT) AS pickup_location_id,
CAST(DOLocationID AS INT) AS dropoff_location_id,
RatecodeID AS rate_code_id,
store_and_fwd_flag,
payment_type,
fare_amount, extra, mta_tax, tip_amount, tolls_amount,
improvement_surcharge, total_amount, congestion_surcharge,
Airport_fee AS airport_fee,
CAST(tpep_pickup_datetime AS DATE) AS pickup_date,
CAST(EXTRACT(HOUR FROM tpep_pickup_datetime) AS INT) AS pickup_hour,
CAST(EXTRACT(DOW FROM tpep_pickup_datetime) AS INT) AS pickup_dow,
ROUND(EXTRACT(EPOCH FROM (tpep_dropoff_datetime - tpep_pickup_datetime)) / 60.0, 2)
AS trip_duration_min
FROM read_parquet('{src}')
WHERE tpep_pickup_datetime IS NOT NULL
AND tpep_dropoff_datetime IS NOT NULL
AND trip_distance > 0
AND fare_amount > 0
AND EXTRACT(YEAR FROM tpep_pickup_datetime) = {year}
AND EXTRACT(MONTH FROM tpep_pickup_datetime) = {month}
""").fetch_arrow_table()
Tüm aylar (Lambda içerisinde istek atılan) işlendikten sonra Arrow tabloları birleştirilerek Iceberg tablosuna tek seferde yazılıyor:
combined = pa.concat_tables(all_arrow_tables)
table.append(combined)
Iceberg tablosu pickup_date üzerinden MonthTransform ile partition’lanıyor. Bu sayede Athena sorguları tarih filtreleme yaparken sadece ilgili partition’ları okuyor.
PREPROCESSED_PARTITION_SPEC = PartitionSpec(
PartitionField(
source_id=20, field_id=1000,
transform=MonthTransform(), name="pickup_month"
)
)
Pipeline #3 | Analytics
Son aşamada işlenmiş Iceberg tablosu PyIceberg scan kullanılarak okunuyor, DuckDB’de tablo olarak register ediliyor ve 4 farklı aggregation sorgusu çalıştırılıyor. Her birinin sonucu ayrı bir Iceberg tablosu olarak yazılıyor.
| Tablo | İçerik |
|---|---|
daily_summary | Günlük seyahat sayısı, ortalama ücret, ortalama mesafe, ortalama süre, toplam tutar |
hourly_pattern | Saat bazlı seyahat sayısı, ortalama ücret, mesafe, süre |
top_routes | En çok kullanılan 50 pickup-dropoff lokasyon çifti |
payment_breakdown | Ödeme tipine göre seyahat sayısı, gelir, ortalama bahşiş |
Örnek sorgu - daily_summary:
SELECT
pickup_date,
COUNT(*)::BIGINT AS trip_count,
ROUND(AVG(fare_amount), 2) AS avg_fare,
ROUND(AVG(trip_distance), 2) AS avg_distance_miles,
ROUND(AVG(trip_duration_min), 2) AS avg_duration_min,
ROUND(SUM(total_amount), 2) AS total_revenue
FROM preprocessed
WHERE EXTRACT(YEAR FROM pickup_date) = 2025
AND EXTRACT(MONTH FROM pickup_date) IN (1, 2, 3)
GROUP BY pickup_date
ORDER BY pickup_date
Sonuç Arrow tablosu olarak alınıp, schema_to_pyarrow ile hedef Iceberg şemasına cast edildikten sonra tabloya yazılıyor:
from pyiceberg.io.pyarrow import schema_to_pyarrow
target_schema = schema_to_pyarrow(config["schema"])
arrow_result = arrow_result.cast(target_schema)
iceberg_table.append(arrow_result)
λ Deployment
Cloud9 içerisinde SAM CLI ve Docker yüklü geliyor o nedenle ekstra bir şey yapmaya gerek yok. İlk adım olan build aşamasında Dockerfile’daki imaj oluşturuluyor. Sonrasında ise sam deploy komutu ile Lambda fonksiyonu AWS’e deploy ediliyor. İlk deployment sırasında SAM size stack adı, region, S3 bucket gibi bilgileri soruyor ve bunları bir kez doldurduktan sonra diğer deployment’larda sadece sam deploy komutunu çalıştırarak güncellemeleri AWS’e gönderebilirsiniz.
Deployment sırasında SAM sizin için arkaplanda bir CloudFormation stack’i oluşturuyor ve kaynakları bu stack üzerinden yönetiyor. Bu örnekte S3 bucket’ı, Lambda fonksiyonu içerisinde kullanılacak Docker imajını barındıracak ECR repository’si ve gerekli IAM rolleri bu stack içerisinde oluşturuluyor.
sam build
# İlk deployment (guided)
sam deploy --guided
# Sonraki deployment'lar
sam deploy
Build ve deployment çıktıları 👇🏻
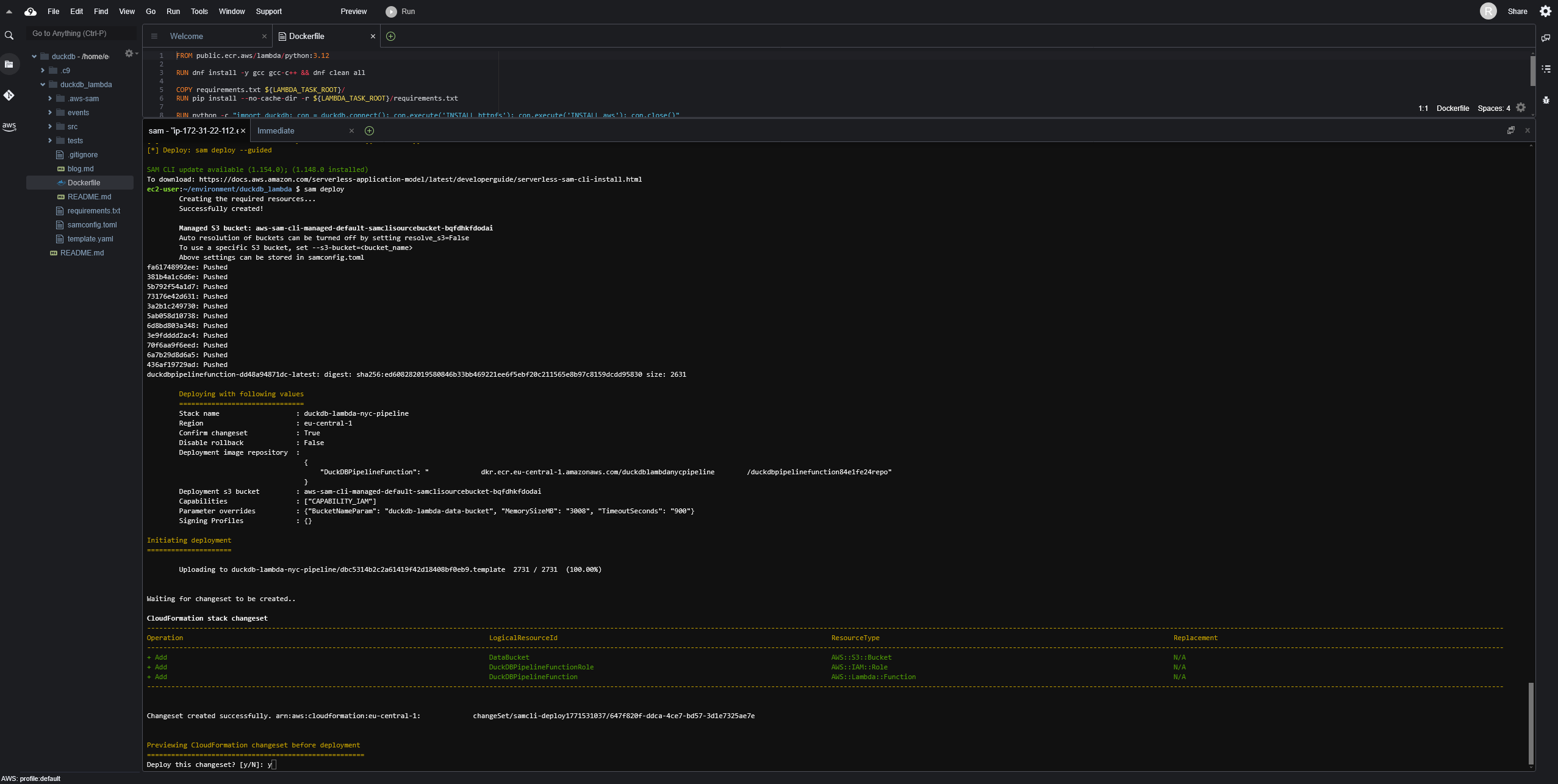
Test
Pipeline’ı test etmek için Cloud9 terminali içerisinde aws lambda invoke komutunu kullanıyoruz. Her aşama sırayla çalıştırılmalı. Eğer lokalde geliştiriyorsanız AWS CLI’nın doğru şekilde yapılandırıldığından ve gerekli izinlere sahip bir IAM kullanıcısı ile giriş yapıldığından emin olun.
# 1. Ingest - ham veriyi S3'e indir
aws lambda invoke --function-name duckdb-nyc-tlc-pipeline \
--cli-binary-format raw-in-base64-out \
--payload '{"stage":"ingest","year":2024,"months":[1,2]}' \
/dev/stdout
# 2. Preprocess - temizle, dönüştür, Iceberg'e yaz
aws lambda invoke --function-name duckdb-nyc-tlc-pipeline \
--cli-binary-format raw-in-base64-out \
--payload '{"stage":"preprocess","year":2024,"months":[1,2]}' \
/dev/stdout
# 3. Analytics - aggregation sorgularını çalıştır
aws lambda invoke --function-name duckdb-nyc-tlc-pipeline \
--cli-binary-format raw-in-base64-out \
--payload '{"stage":"analytics","year":2024,"months":[1,2]}' \
/dev/stdout
Her aşamanın çıktısında işlenen satır sayıları ve durumlar dönüyor:
{
"statusCode": 200, "body": "{\"stage\": \"ingest\", \"year\": 2024, \"files\": [{\"month\": 1, \"rows\": 2964624, \"status\": \"ok\"}, {\"month\": 2, \"rows\": 3007526, \"status\": \"ok\"}]}"}
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}

Athena ile Sorgulama
Pipeline tamamlandıktan sonra tüm tablolar Glue Data Catalog’da nyc_tlc database’i altında görünür. Athena ile doğrudan sorgulanabilir.

-- Preprocessed tablodaki toplam satır sayısı
SELECT COUNT(*) FROM nyc_tlc.yellow_trips_preprocessed;
-- Günlük özet
SELECT * FROM nyc_tlc.daily_summary ORDER BY pickup_date;
-- En yoğun saatler
SELECT * FROM nyc_tlc.hourly_pattern ORDER BY trip_count DESC;
-- En popüler rotalar
SELECT * FROM nyc_tlc.top_routes;
-- Ödeme tipi dağılımı
SELECT * FROM nyc_tlc.payment_breakdown;
nyc_tlc.yellow_trips_preprocessed ve nyc_tlc.daily_summary tablolarından örnek sorgu sonuçları 👇🏻
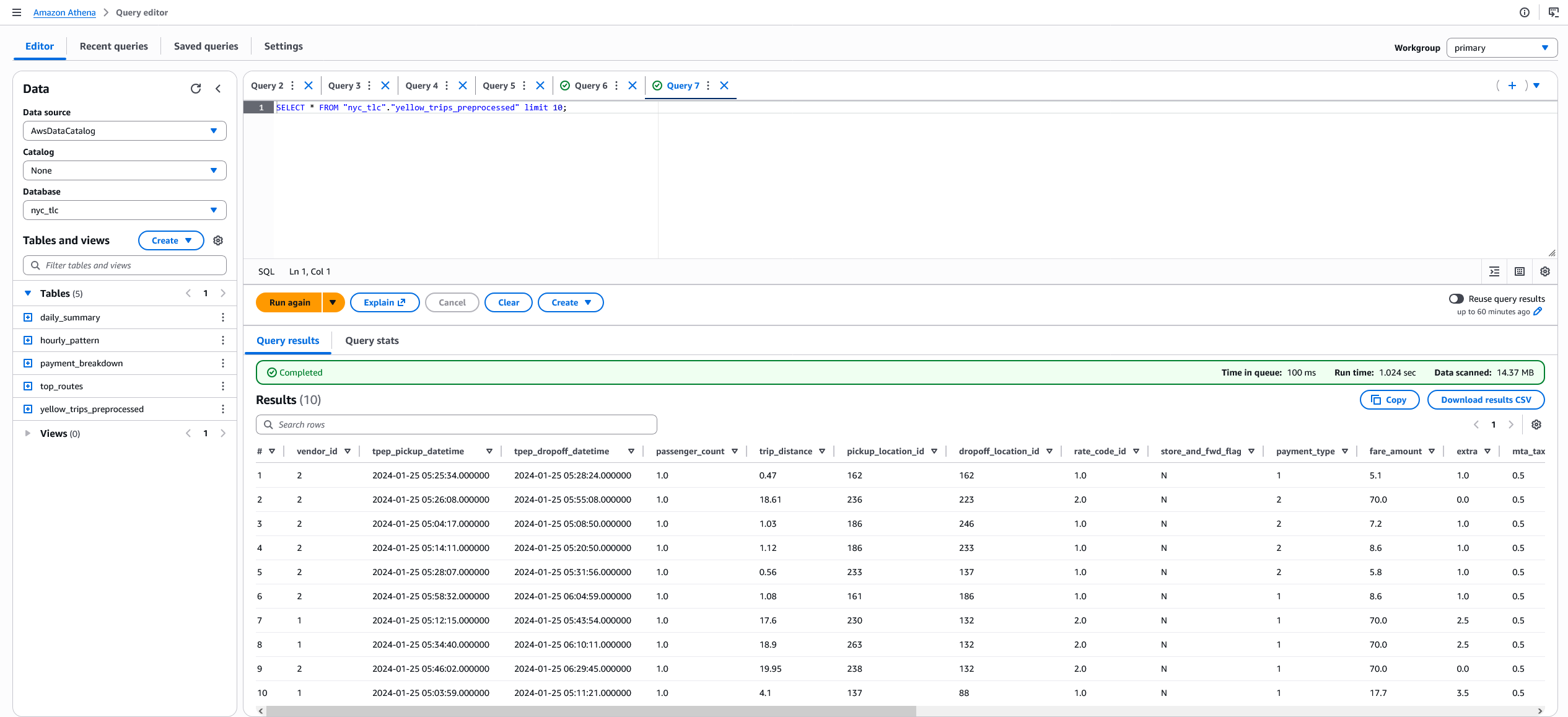
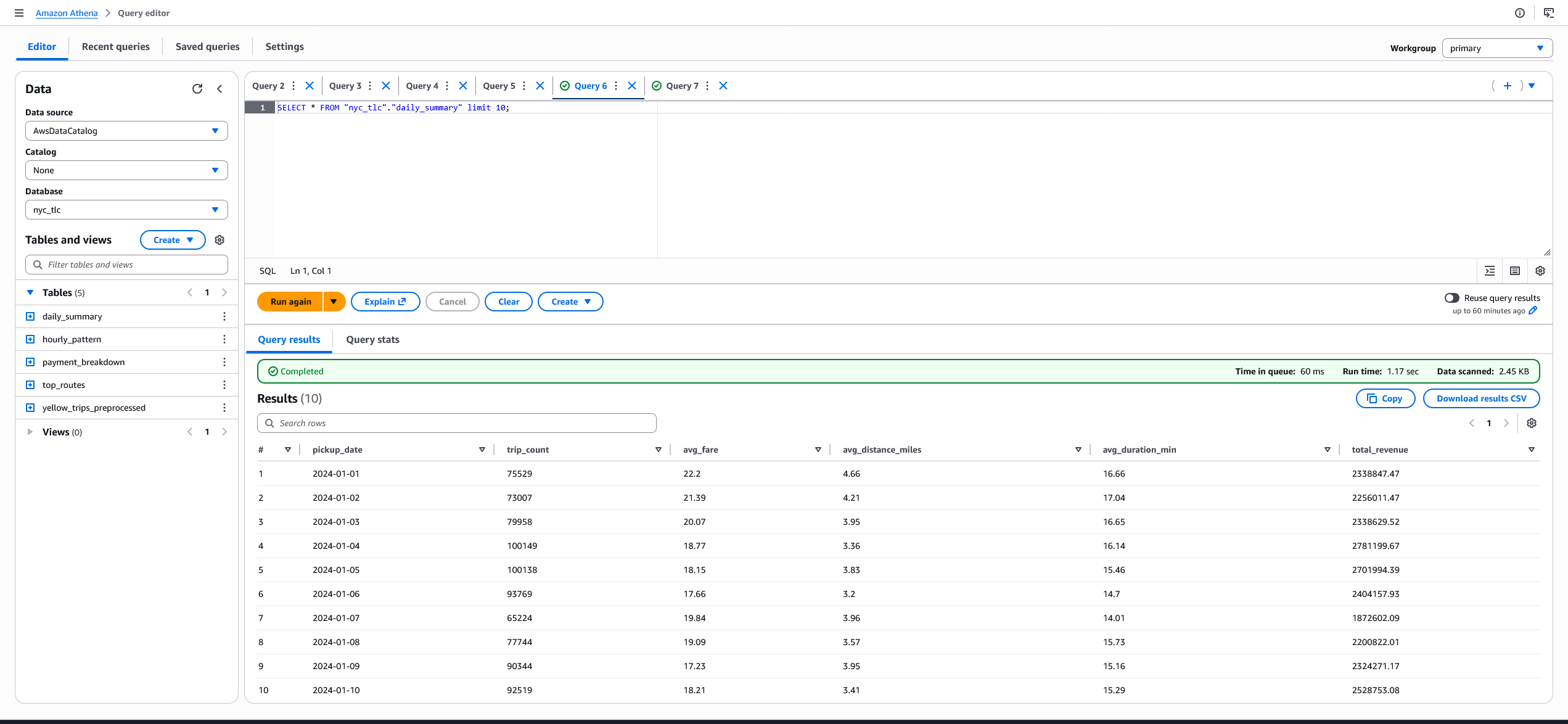
Athena'da Iceberg tabloları sorgulamak için workgroup'un Engine v3 kullanması gerekiyor, seçili değilse sorgular hata verebilir.
Bu projede DuckDB’nin S3 üzerinden doğrudan parquet okuma/yazma, SQL ile dönüşüm yapma ve PyArrow ile entegrasyon yeteneklerini kullanarak serverless bir veri pipeline’ı oluşturduk. PyIceberg ile Glue Data Catalog’a tablo kaydı yaparak Athena ile doğrudan sorgulanabilir tablolar elde ettik.
DuckDB’nin Lambda üzerinde çalışması in-memory bir analitik motoru serverless olarak sunma imkanı sağlıyor. 4 GB bellek ile birkaç milyon satırlık veri setlerini işlemek rahatlıkla mümkün. Daha büyük veri setleri için ise Lambda’nın timeout ve bellek sınırlarını göz önünde bulundurmak gerekiyor.
Son olarak tüm akışı silmek isterseniz de sam delete komutunu kullanabilir veya konsolda ilgili CloudFormation stack’ini silebilirsiniz.
Pipeline’ın tamamına silverstone1903/serverless-duckdb üzerinden erişebilirsiniz.
Not: handler.py kodunun yazımında Claude Opus 4.6'dan yararlandım.
Kaynaklar
- DuckDB Documentation
- PyIceberg Documentation
- AWS SAM Developer Guide
- NYC TLC Trip Record Data
- Apache Iceberg
- Amazon Athena Iceberg Tables
[Build an ETL Pipeline using AWS Lambda, S3, Glue & AWS DynamoDB Big Data Project](https://www.youtube.com/watch?v=ur9H68DmhVM)


