
Ollama Deneyleri Serisi: Text2SQL Asistanı
Published:

![]()
![]()

Giriş
Herhalde yazarken en uzun vakit ayırdığım yazılardan biri oldu bu. Basit bir amaçla başlayıp birden fazla mimari katmanın olduğu bir projeye dönüştü. Bu yazının yazılabilir hale gelmesi 1 ayı geçkin bir süre aldı, o nedenle de en uzun yazılarımdan biri olmaya aday. Girişi bile bu nedenle uzun olacak 🤣
Bu proje için başlangıç noktam Ollama ile lokalde çalışan basit bir Text2SQL demo’su yapmaktı (daha önce ollama ile yazdığım Asistan yapan asistan yazısı buradan). Ama zaman geçtikçe LLM’in SQL üretmesinin ötesine geçip bu süreci nasıl güvenli ve tekrarlanabilir bir şekilde tasarlayabileceğimi düşünmeye başladım. Bununla birlikte güvenlik katmanını sadece LLM boyutunda değil API ve veritabanı tarafında da nasıl sağlayabileceğimi düşündüm. Sonuçta ortaya çıkan proje temel olarak kullanıcından gelen soruyu SQL’e çeviren ve sonucunu gösteren basit bir arayüz olsa da arkasında oldukça sağlam bir mimari ve güvenlik katmanı oluştu.
Bahsettiğim katmanlar süreç ilerledikçe ortaya çıktı ama kısaca özetlemek gerekirse ilk olarak API tarafında daha önce hiç kullanmadığım Rate limiting ve Request logging aşamasıydı. Rate limiting, güvenli servis tasarımı konusunda ilk akla gelen konu olduğu için zaten halihazırda çözümü olan bir problemdi aslında. O nedenle mevcut çözümler üzerinden ilerlemek işimi kolaylaştırdı12. Bir diğer denemek istediğim konu ise FastAPI içerisinde Middleware3 yapısını kullanarak bu katmanları uygulamaktı. Bu yüzden işin bir kısmı mimari tasarım ve güvenlik üzerine oldu. Diğer yandan arayüz tarafında da Streamlit ile hızlı ve sade bir arayüz tercih ettim. Sonuçta ortaya çıkan ürünün hem mimari olarak sağlam hem de kullanıcı deneyimi olarak basit olmasını amaçladım.
Bu yazıda büyük dil modellerinin (LLM) veritabanlarıyla nasıl etkileşime girebileceğini ve bu süreci güvenli, tekrarlanabilir ve tamamen lokalde çalışacak bir şekilde nasıl tasarlayabileceğimizi anlatacağım. Özellikle veritabanına doğal dilde sorular sorarak SQL sorguları üretmek ve bu sorguları doğrulayıp çalıştırmak üzerine odaklanacağız. Sonuçları ise Streamlit arayüzünde görselleştireceğiz.
Bu projede veri tarafında da çok büyük ama anlamsız bir yapı yerine daha raporlama odaklı bir şema tercih edildi. Veriler faker kullanılarak (biraz da Excel dokunuşu 🧂) ile oluşturuldu. Oluşturulan tablolar:
customersproductsordersorder_items
DB aşamasına ait kodlara backend/db/init klasöründen erişebilirsiniz.
Proje yapısı ve akışı oldukça basit. Amaç sadece LLM SQL yazıyor demek değil aynı zamanda süreci mimari olarak nasıl tasarladığımızı, hangi kararları neden verdiğimizi ve ortaya çıkan ürünün nasıl çalıştığını göstermek. Ana bileşenler 👇🏻
- Ollama: Lokal model servis katmanı
- FastAPI: Servis (Backend API)
- Streamlit: Arayüz (UI)
- PostgreSQL: Veri kaynağı
Mimari
Projeyi tasarlarken uygulanan kısıtlar ise aşağıdaki gibi 👇🏻
- Lokalde çalışma: İstekler dışarı çıkmasın, veri içeride kalsın.
- Read-only (least-privilege) yaklaşımı: Sorgu tarafı
SELECTodaklı olsun. - LLM güvenliği: Kullanılması istenmeyen komutları engelle, hatalı sorguda tekrar dene.
- UI sadeliği: Karmaşık akış backend tarafında kalsın.
- Kullanım & kurulum kolaylığı: Uygulama tek komutla ayağa kalksın, Docker Compose ile yönetilsin.
Kullanılan modeller:
qwen2.5-coder:14b: Kod ve SQL yazma konusunda yerelde çalıştırılabilecek en başarılı modellerden biri. Sadece SQL oluşturmak için kullanılıyor.
llama3:8b: Veritabanından dönen ham (raw) veriyi analiz edip son kullanıcıya Türkçe/İngilizce doğal dilde özetlemek (narration) için kullanılıyor.
Akış 5 adımdan oluşuyor:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌───────────────┐ ┌──────────────┐
│ Şema Okuma │──►│ SQL Üretimi │──►│ SQL Doğrulama│──►│ SQL Çalıştırma│──►│ Özetleme │
│ (PostgreSQL) │ │ (qwen2.5) │ │ (Validator) │ │ (PostgreSQL) │ │ (llama3) │
└──────────────┘ └──────────────┘ └──────────────┘ └───────────────┘ └──────────────┘
Uygulama
Uygulama tarafında sistem 3 ana bileşenden oluşuyor: Streamlit (frontend), FastAPI (backend) ve PostgreSQL (veritabanı). Ollama ise bunların yanında çalışan lokal model servisi. Yani kullanıcı doğrudan modele değil önce Streamlit arayüz aracılığı ile servise gidiyor. FastAPI de ihtiyaca göre PostgreSQL ve Ollama’ya gidiyor.
Backend tarafında middleware bileşenleri de aşağıdaki gibi:
- RequestLogging: Her isteği ve süresini log’luyor.
- RateLimit: IP bazlı istek sınırı uyguluyor.
Backend: Uygulama Motoru
backend klasörü aşağıdakilerden meydana geliyor 👇🏻
main.py: Endpoint’ler, WebSocket akışı ve orchestrator yönetimi.middleware.py: Request log’lama ve rate limit.agents/: Şema okuma, SQL yazma, SQL doğrulama (validation), sorgu çalıştırma (execution) ve özetleme (narration) adımlarının ayrıştırıldığı katman.models/schemas.py: API için gerekli şemalar (request/response modelleri).config.py: Tüm ayarları.envüzerinden okuyup tek merkezden yöneten config management.
FastAPI
Backend’de sadece /query yok operasyonu izlemek için /health, /schema, /stats, /history, /cache/clear ve streaming için /ws/query de var. /health endpoint’inde Ollama ve DB ayrı ayrı kontrol edilip durum healthy/degraded olarak dönüyor ve arayüzde gösteriliyor. Rate limiter tarafında da küçük ama kritik bir tercih var: /health, /schema, /docs endpoint’ler hariç tutuldu, bu monitoring endpoint’leri rate limitten etkilenmiyor. Endpoint’ler aşağıdaki gibi 👇🏻
| Endpoint | İşlev |
|---|---|
/query | Doğal dil sorusunu işler |
/schema | Tablolar ve kolon metadata’sını döner |
/health | Ollama + database durumunu kontrol eder |
/history | Son sorguları listeler |
/stats | Cache ve history boyutlarını döner |
/cache/clear | In-memory cache’i temizler |
/ws/query | Streaming query akışı sağlar |
 schema endpoint'inin döndürdüğü veri
schema endpoint'inin döndürdüğü veri Orchestrator Akışı
Orchestrator tarafı tek bir method çağrısı gibi görünse de içeride adım adım ilerliyor:
- Şema yükleniyor (
SchemaManager) - SQL üretiliyor (
SQLGenerator) - SQL doğrulanıyor (
SQLValidator) - Sorgu çalıştırılıyor (
SQLExecutor) - Sonuç özetleniyor (
Narrator)
İlk aşamada modelin veritabanında ne olduğunu bilmesi gerekiyor. SchemaManager tabloları/kolonları okuyor ve LLM’e uygun formata çeviriyor.
Sonrasında kullanıcı sorusu + şema birlikte SQLGenerator üzerinden Ollama’ya gidiyor:
question = "En yüksek ciroya sahip ilk 5 ürün nedir?"
schema_text = self._schema_mgr.format_schema_for_llm()
generated_sql = await self._sql_gen.generate(question, schema_text)
Modele yalnızca soru verilmiyor, şema metni de dahil ediliyor. Yani LLM’in tablo/kolon adlarını kendi kafasına göre uydurması yerine elindeki bağlamı artırıyoruz. Böylece hem join senaryoları hem de aggregation senaryoları rahat test edilebiliyor.
Sorgu Güvenliği
LLM’in ürettiği SQL’i direkt çalıştırmak istemiyoruz. O nedenle Burada SQLValidator ile (regex) kontrolden geçiriyoruz. Bu nedenle SQLValidator tarafında birden fazla güvenlik katmanı var:
- Yalnızca
SELECT/WITHbaşlangıcına izin veriliyor. INSERT/UPDATE/DELETE/DROP/ALTER/TRUNCATE/...gibi komutlar regex ile bloklanıyor.- Çoklu statement denemeleri engelleniyor.
- İzin verilen tablo listesiyle whitelist kontrolü yapılıyor.
SQLExecutor ve SQLValidator tarafında da ek önlemler var 👇🏻
- Sorguda
LIMITyoksa otomatik ekleniyor (MAX_ROWS=500). - Her sorguya local statement timeout uygulanıyor (
STATEMENT_TIMEOUT_MS=30000). - Uygulama seviyesinde yalnızca güvenli sorgulara izin veriliyor.
- SQL validator tarafında yasaklı kalıplar engelleniyor.
- Veritabanında agent için ayrı bir read-only kullanıcı kullanılıyor.
- Bağlantı read-only engine üzerinden çalışıyor.
Hatalı/tehlikeli bir SQL gelirse de akış şu:
- SQL geçersiz 👉🏻 hataları belirle
- modele geri besle
- yeniden dene
result = self._sql_validator.validate(generated_sql)
if not result.is_valid:
question_with_feedback = (
f"{question}\n\nIMPORTANT: Your previous SQL had errors: "
f"{'; '.join(result.errors)}. Please fix these issues and generate a correct SELECT query."
)
Güvenlik sadece prompt’a dikkat et seviyesinde değil kod seviyesinde katmanlı bir yaklaşım var.
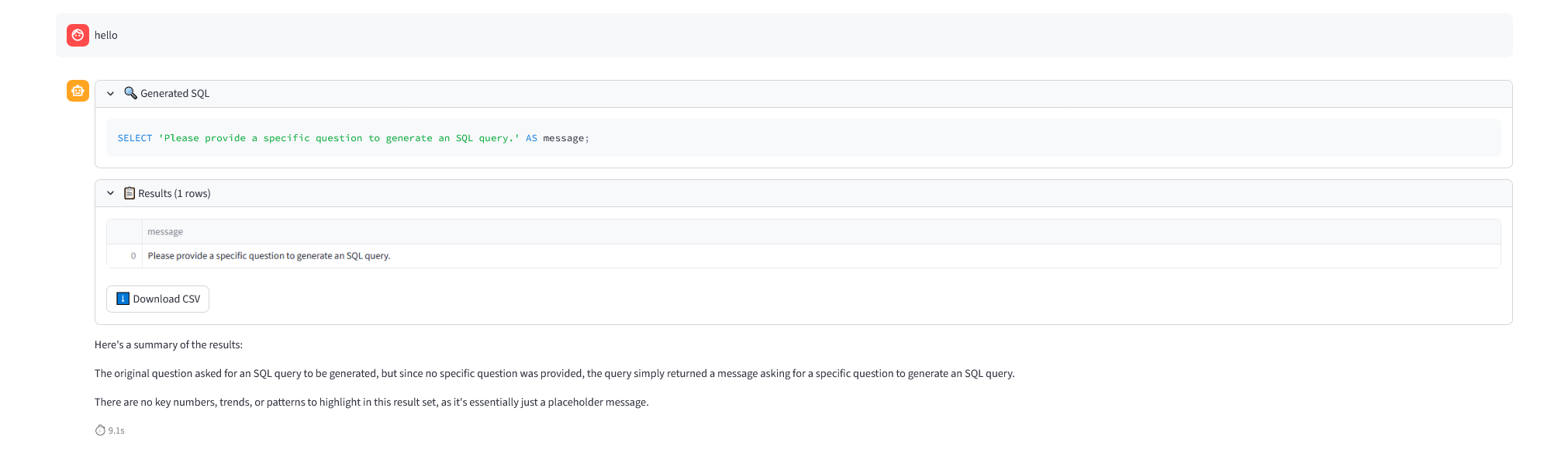 Prompt sadece SQL yazmaya programlı olduğundan hata mesajını bile SQL olarak yazıyor 😅
Prompt sadece SQL yazmaya programlı olduğundan hata mesajını bile SQL olarak yazıyor 😅WebSocket Streaming
/ws/query endpoint’iyle soru tek seferde bekletilmiyor ve pipeline adımları event bazlı akıyor. Örneğin istemciye sırayla status, sql, data, summary_token, done event’leri gidebiliyor. WebSocket burada sorgu bittiğinde tek cevap dönmek yerine süreci adım adım gösterebilmek için kullanıldı. Özetleme token bazlı geldiği için kullanıcı beklerken metin akarak görülüyor. Bununla birlikte sürekli polling yapmak yerine tek ve kalıcı bir bağlantı üzerinden akış sağlanıyor.
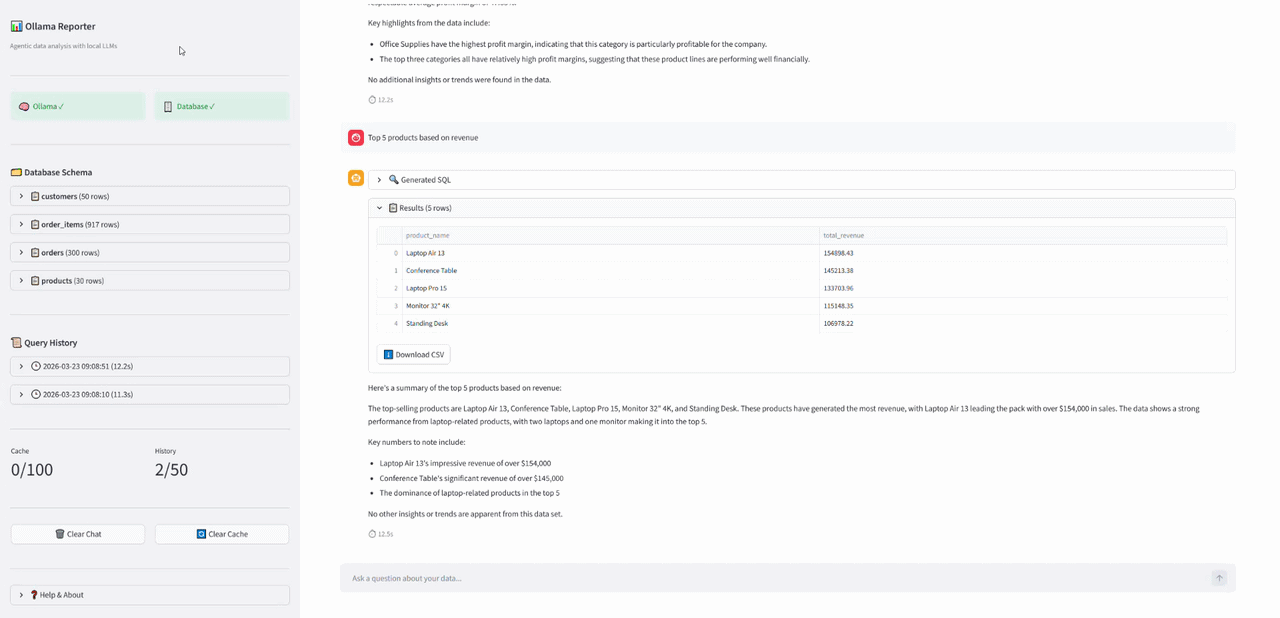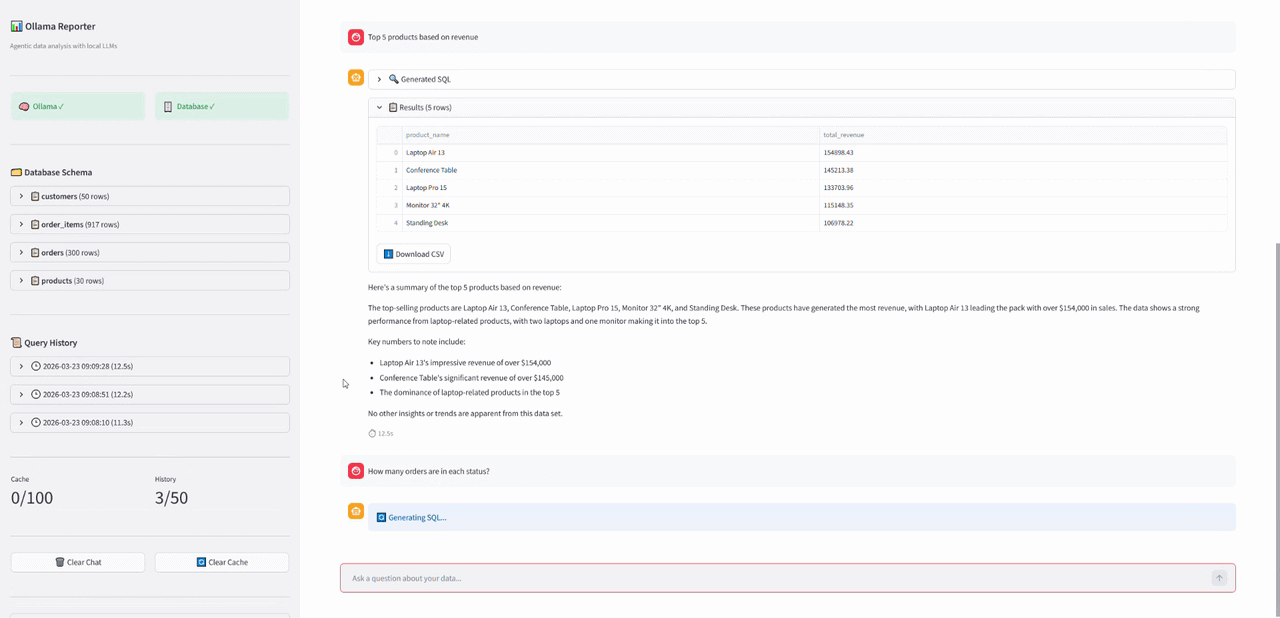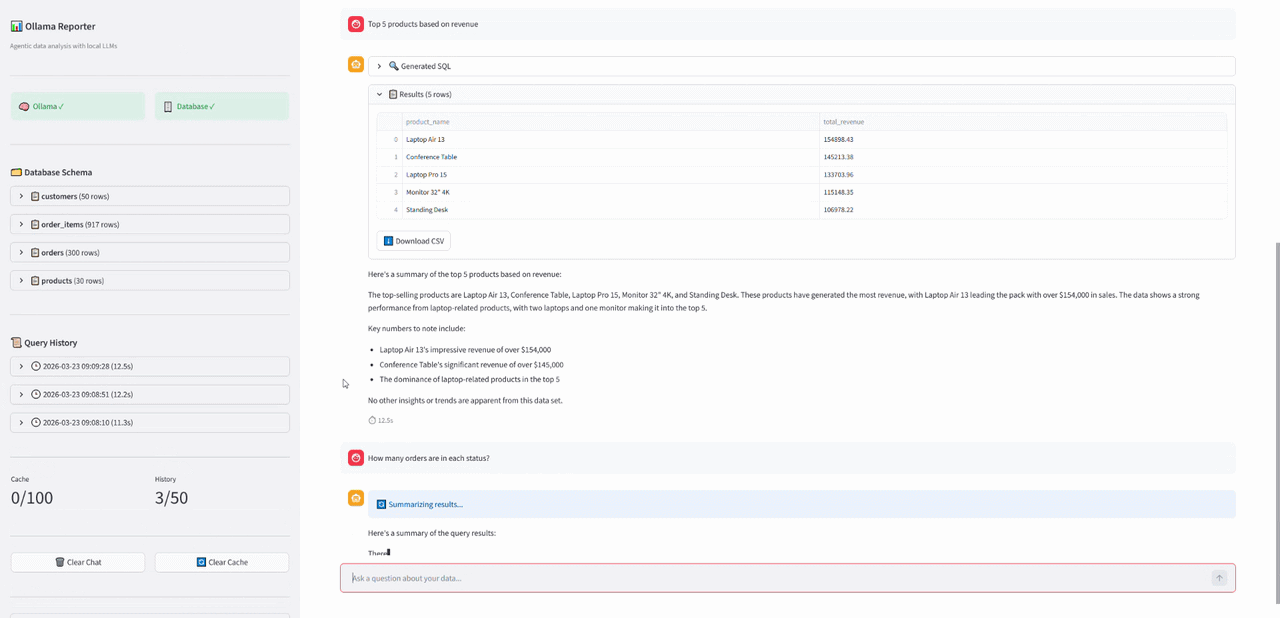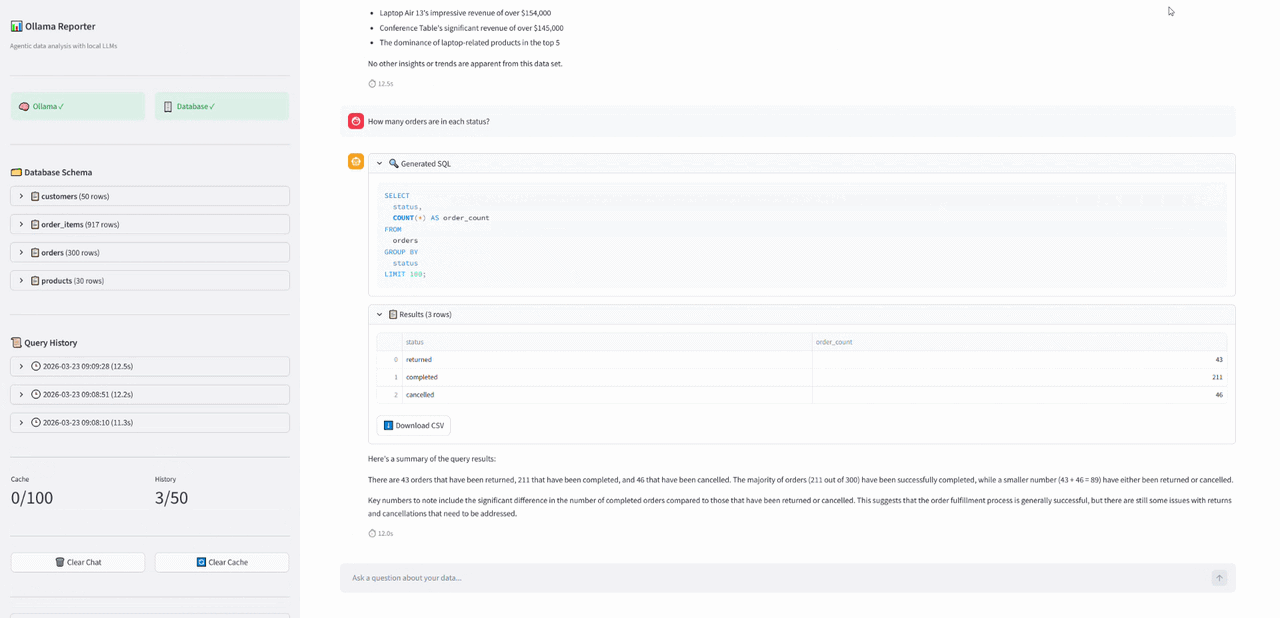 WebSocket üzerinden adım adım giden event'ler. Özet dataframe'den önce geliyor stream olduğu için 😅
WebSocket üzerinden adım adım giden event'ler. Özet dataframe'den önce geliyor stream olduğu için 😅 Sorgu Çalıştırma ve Özetleme
SQL validasyondan geçince PostgreSQL’de çalıştırıyoruz. Sonuçları sadece tablo olarak vermek yerine llama3 ile özetliyoruz.
FastAPI tarafında temel akış:
@app.post("/query", response_model=QueryResponse)
async def query(request: QueryRequest):
orch = get_orchestrator()
result = await orch.query(request.question)
if result.error:
raise HTTPException(status_code=400, detail=result.error)
return _map_result(result)
Burada QueryResponse ile istemciye yalnızca sonuç satırları dönmüyoruz. Aynı zamanda:
- kullanıcının sorusunu,
- üretilen SQL’i,
- ham sonucu,
- satır sayısını,
- doğal dil özetini,
- süre bilgisini
tek bir response model içinde dönüyoruz, bu durum frontend tarafını ciddi anlamda sadeleştiriyor. UI ayrıca ekstra birleştirme yapmak zorunda kalmıyor.
Streamlit Arayüzü
Backend her ne kadar karmaşık bir akışı yönetse de Streamlit ile arayüzü olabildiğince basit bir formda tuttum. Solda şemadaki mevcut tabloları görebildiğimiz ortada ise mesajlaşma ekranı olan bir asistan arayüzü bizi karşılıyor.
Oluşturduğumuz Streamlit akışı aşağıdaki gibi 👇🏻
def handle_question(question: str) -> None:
st.session_state.messages.append({"role": "user", "content": question})
with st.chat_message("assistant"):
result = api_post("/query", {"question": question}, timeout=60)
if result and not result.get("error"):
st.markdown(result["summary"])
st.code(result["generated_sql"], language="sql")
st.dataframe(pd.DataFrame(result["raw_results"]))
Arayüzde ayrıca;
- Sidebar içinde canlı health göstergesi var
- Şema browser ile tablolar ve kolon tipleri görülebiliyor
- Sorgu geçmişi arayüzden tekrar çalıştırılabiliyor
- Sonuçlar CSV olarak indirilebiliyor
- Hiç mesaj yokken örnek sorular buton olarak gösteriliyor
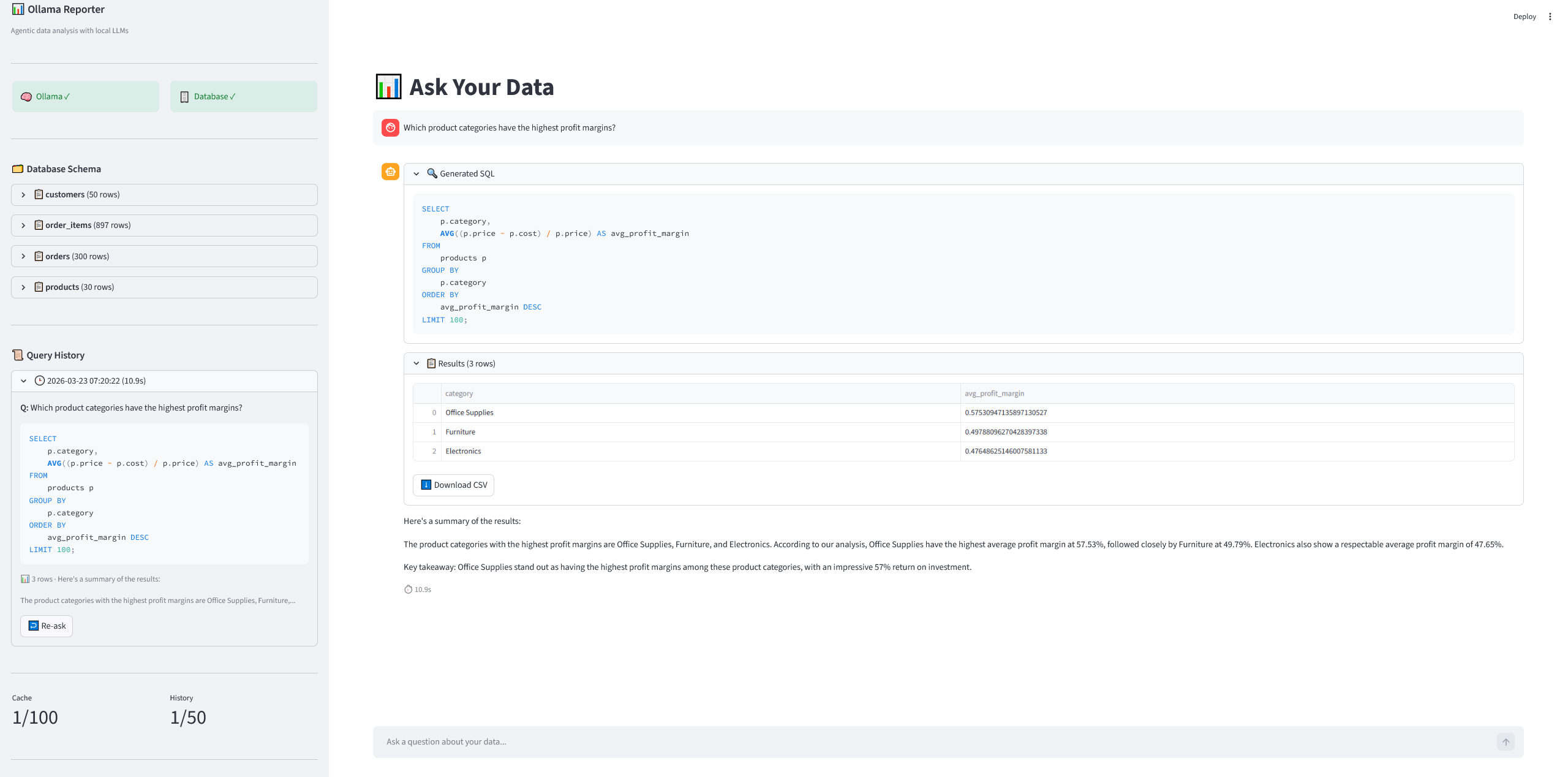
Kurulum ve Çalıştırma
Servislerin hepsi tek bir docker-compose.yml ile ayağa kalkıyor. Projeyi ayağa kaldırmadan önce makinenizde Ollama’nın kurulu olduğundan emin olun ve kullanacağınız modelleri (VRam tercihinize göre) indirin:
ollama pull qwen2.5-coder:14b
ollama pull llama3:8b
Sonrasında servisleri ayağa kaldırıyoruz:
docker compose up -d --build
API backend localhost:8000‘de arayüz ise localhost:8501 adresinde hazır hale gelecektir. Benim gözlemimle istek karmaşıklığı, model performansı ve tabii ki GPU’ya göre sorguların tamamlanıp özetlenmesi ortalama 10-20 saniye sürmektedir.
Uygulama ayağa kalktıktan sonra kontrol etmek için /health endpoint’ine gidebilirsiniz:
curl http://localhost:8000/health
Cache ve geçmiş bilgisini görmek için de aşağıdaki endpoint’lere bakabilirsiniz 👇🏻
curl http://localhost:8000/stats
curl http://localhost:8000/history
Lokal bir modelin doğrudan veritabanı verisine erişerek Text-to-SQL yapması artık hem ucuz hem de qwen2.5-coder gibi modellerle oldukça tutarlı. Buradaki kritik nokta LLM’i kontrolsüz bırakmamak, girdi ve çıktıları validator katmanıyla doğrulamak. Bu proje ile birlikte LLM’lerin veritabanlarıyla nasıl güvenli bir şekilde etkileşime girebileceğini, bu süreci nasıl mimari olarak tasarlayabileceğimizi ve ortaya çıkan ürünün nasıl çalıştığını göstermeye çalıştım.
Kodun tamamına silverstone1903/ollama_reporter üzerinden erişebilirsiniz.
Not: Kodların yazımında Claude Opus 4.6'dan ve Codex 5.3'ten yararlandım.
