Serverless ATS: Amazon Bedrock ile CV Analizi
Published:
![]()


Giriş
Serverless ve GenAI ikilisini basitçe nasıl kullanabilirim diye düşünürken aklıma iş başvuru sürecinde kullanılan ATS (Applicant Tracking System) uygulamaları geldi. Adayların CV’lerini yükleyip, bu CV’lerin içeriğini otomatik olarak okuyup değerlendiren bir sistem kurmak hem serverless kullanarak hızlıca prototiplemek hem de Amazon Bedrock’u biraz deneyimlemek için bir hayli aklıma yattı. Bu fikri ete kemiğe büründürmek amacıyla serverless mimari ve Amazon Bedrock (GenAI) kullanarak nasıl akıllı bir CV inceleme uygulaması (ATS) geliştirdiğimizi adım adım anlatacağım. Amaç adayların yüklediği PDF veya Word formatındaki CV’leri otomatik olarak okuyan, arka planda Amazon Bedrock ile değerlendirip puanlayan ve sonuçları DynamoDB’ye kaydeden tam otomatik bir akış (pipeline) kurmak.
Mimari
Projeyi tasarlarken temel amacımız uygulamayı hızlı ayağa kaldırmak ve yönetilen (fully-managed) servislerle sunucu bakım maliyetinden kaçınmaktı. Bu yüzden altyapıyı AWS üzerine tamamen serverless olarak kurguladık.
Mimari Akışı (Architecture) 🔓
graph TD
subgraph Frontend
A[Candidate - UI] -->|Selected Job & Upload CV| B[API Gateway Presigned URL]
end
subgraph AWS Pipeline
B -->|PUT Object| C(Amazon S3 - raw bucket)
C -->|S3 Event Trigger| D{AWS Lambda - Parser & ATS}
D -->|Text Extraction| E[pypdf / python-docx]
E -->|Prompt + CV Text| F[Amazon Bedrock]
F -->|amazon.nova-pro-v1:0| D
D -->|Evaluation Record| G[(Amazon DynamoDB)]
end
subgraph Notifications
D -->|If Score > Threshold| H[Amazon SNS]
H -->|Email Notification| I[HR Expert]
end
Projeyi şekillendirirken koyduğumuz bazı kısıtlar var tabii ki.
- Sadece İstenen Formatta Çalışma: JSON yapılarına sadık kalmak ve Lambda tarafında parsing (ayrıştırma) hatası almamak için Bedrock modelini yalnızca JSON çıktısı verecek şekilde (strict output) programladık.
- Geçici Veri Yönetimi: Adaylar tarafından yüklenen dosyalar Lambda içerisinde sadece bellekte (in-memory) işlendi. İşlem tamamlandığında veri bellekte tutulmadığı için içerik kalıcı olarak saklanmadı.
Bu kısıtlar doğrultusunda kullanılan servisler de aşağıdaki gibi şekillendi 👇🏻
- Amazon S3 & AWS Lambda: S3, depolama ve tetikleyici görevi görürken Lambda tüm sürecin yönetildiği ara katman görevi gördü.
- Amazon Bedrock: GenAI tarafında Amazon’un sunduğu Nova 1 Pro modelini tercih ettim. Fiyat/performans açısından CV metinleri ve büyük promptları işlerken hem oldukça başarılıydı hem de temperature değerini en düşüğe (
0.1) çekince belirlediğim katı kurallardan sapmadı (belirlenen eşiği geçiremeyince bazen sapsa dediğim oldu 😂). - Amazon DynamoDB & SNS: Sonuçların key-value formatında saklanabilmesi için DynamoDB ve skorlanan CV’ye ait skorun belirlenen eşiğin üstünde olmas durumunda ilgili ekiplere mail atabilmek için de SNS tercih edildi.
- Python Kütüphaneleri: PDF’lerden metin çıkarmak için
pypdf, Word dökümanları için isepython-docxkütüphanesi kullanıldı.
Prompt’un Belirlenmesi
Projeyi geliştirirken karşılaştığım en büyük zorluk dil modellerinin (LLM) insanları kırmamaya programlanmış olması ve adaya kötü demekten çekinmesiydi. Çok alakasız bir profilin veri bilimci ilanına başvurduğunu senaryoda model adayın CV’sinde geçen Excel ifadesini görüp “adayın sayısal yatkınlığı var” diyerek 100 üzerinden 85 puan verebiliyordu. Bu problemini çözmek için prompt yapımızı şu şekilde kurguladık:
- Elenme (Knock-out) Kuralları: Örneğin adayın sektör veya rol geçmişi pozisyonla açık biçimde uyuşmuyorsa (ör. ML Engineer -> QA Engineer) toplam puanın belli bir seviyenin üzerine çıkmamasını açık kurallarla modele belirttik.
- Mantık Yürütme (Chain of Thought ): Modelden doğrudan skor istemedik. Her bir kategori için (deneyim, yetenek, eğitim vb.) önce
reasoning(mantık) metnini oluşturmasını, sonra skoru vermesini istedik. Böylece model kendi yazdığı değerlendirmeyle çelişen yüksek puanları daha az vermeye başladı.
Nova’ya atılan isteğin genel yapısı aşağıdaki gibiydi 👇🏻
body = json.dumps({
"system": [{"text": "You are an expert HR manager and ATS system prioritizing strict JSON outputs without markdown."}],
"messages": [{"role": "user", "content": [{"text": prompt}]}],
"inferenceConfig": {"maxTokens": 1000, "temperature": 0.1}
})
response = bedrock_client.invoke_model(
body=body,
modelId=BEDROCK_MODEL_ID,
accept="application/json",
contentType="application/json",
)
Bu promptun içerisine JSON şemasını besleyip modelden yalnızca bizim belirlediğimiz formlarda (Listeler, metin vb.) çıktı almaya zorladık.
prompt = f"""You are a professional, objective, and fair technical recruiter...
CRITICAL INSTRUCTION: You must evaluate the candidate holistically...
SCORING GUIDELINES & RULES:
1. Evaluate based on evidence. You can reasonably infer basic familiarity if strong related skills exist (e.g., knowing React implies some knowledge of JavaScript).
2. Wrong Field: If the candidate's core roles are largely unrelated to the job field, reflect this with a lower score (e.g., cap around 50), but be sure to acknowledge any relevant side projects, certifications, or hobbies.
...
JSON SCHEMA:
must_have_requirements
],
"nice_to_have_requirements": [
],
"gaps": ["specific gap 1", "specific gap 2"],
"risk_flags": ["missing years of experience", "seniority mismatch", "required technology not evidenced"],
"strengths": ["specific matching strength 1", "specific matching strength 2"],
"dimension_evaluations": experience_match,
...
}},
"summary": "Objective and constructive 3-sentence summary of candidate fit detailing their strengths and areas for improvement.",
...
}}
"""
Test
Uygulamanın çalışıp çalışmadığını, Not Şişirme sorununun geride kalıp kalmadığını test etmek için çok fazla CV’ye ihtiyacımız vardı. Tüm bunları elimle yazamayacağım için yine LLM’lerden yardım aldım.
Lokal ortamda faker ve Ollama (qwen3:4b modeli) kullanarak rastgele sahte (mock) CV’ler oluşturan bir Python scripti oluşturdum. Farklı sektörlerden, farklı deneyim seviyelerinden ve farklı yetenek kombinasyonlarından adaylar türeterek modelin değerlendirme kriterlerini gerçekçi bir şekilde test edebilmemize olanak sağladı. Bu script:
Fakerkütüphanesiyle sahte isim, e-posta, telefon ve sektör oluşturuyor.- Adayları rastgele olarak “Çok İyi Eşleşen” (strong match) veya “Alakasız” (weak) olacak şekilde iki profile ayırıyor.
- Klasik, Modern, Akademik ve yazılı (narrative) gibi farklı görsel düzenler ile bu verileri PDF veya DOCX dosyası olarak hazır hale getiriyor. Hem de rastgele bir şekilde italik, kalın yazı formatlarını (
python-docxvefpdf2kullanarak) uyguluyor.
qwen3 ile generate_test_data.py scriptimiz içerisinde gönderdiğimiz istek aşağıdaki gibi 👇🏻
payload = {
"model": "qwen3:4b",
"prompt": f"Write a realistic CV for '{candidate_name}' focusing on these key skills: {', '.join(job.get('must_have_skills', []))}...",
"stream": False,
"options": {"temperature": 0.7} # biraz sallasın diye yüksek verdik 😂
}
response = requests.post("http://localhost:11434/api/generate", json=payload)
cv_text = response.json().get("response", "")
Script’i çalıştırırken eksik paketleri yüklemeye çok üşendiğim için de uv run generate_test_data.py komutunu kullandım ve bu sayede uv otomatik olarak eksik paketleri yükleyip scripti çalıştırdı.
Bu sayede farklı roller için test CV’lerini kısa sürede Lambda ve Bedrock tarafından işlenebilecek biçimde hazırlamış oldum. Oluşturulan CV’leri test_cvs klasörü altında PDF ve DOCX formatlarında bulabilirsiniz. İlgili script’i de burada yer alıyor.
Arayüz
İlan başvurularının alınabilmesi için Gemini kullanarak Tailwind CSS tabanlı basit bir arayüz hazırladım. Bu arayüzde adaylar ilan detaylarını görüntüleyebiliyor ve CV’lerini yükleyebiliyor. Form gönderildiğinde dosya, API Gateway üzerinden S3’e yüklenecek şekilde akışa dahil ediliyor.

AWS SAM ile Canlıya Alma
Bütün bu mimariyi AWS konsolunda tek tek el ile oluşturmak çok tercih edilen bir pratik olmadığı için S3, Lambda fonksiyonları, API Gateway ve DynamoDB’yi template.yaml ile tanımlayarak AWS SAM kullanarak paketledim ve deploy ettim. IAM Log politikaları, Bucket tetikleyiciler gibi ayarlar Serverless Framework ile yaml üzerinden kodlandı. Aradaki bazı adımlarda ben elle müdahale edip konsol üzerinden bazı izinler tanımladım ama kod kısmı neredeyse tamamen altyapıyı tanımlayan template.yaml dosyası üzerinden ilerledi.
sam build --use-container && sam deploy
Bu komutun ardından SAM arka planda CloudFormation kullanarak gerekli kaynakları oluşturdu; Lambda tetikleyicileri, roller ve diğer bağımlılıklar eksiksiz biçimde ayağa kalktı.
Bu süreçte daha pratik olduğu için Cloud9 kullandım. Böylece AWS kaynaklarına erişim ve izin yönetimiyle lokal ortamda ayrıca uğraşmadan doğrudan cloud ortamında geliştirmeyi tamamlayabildim. AWS SAM kullanımıyla ilgili benzer bir örneği daha önce Serverless Veri Akışı: DuckDB, Lambda ve Apache Iceberg ile NYC Taksi Verisi yazısında da paylaşmıştım.
Sonuç
Bu projede serverless mimari ile üretken yapay zekayı, işe alım gibi gerçek bir kullanım senaryosunda bir araya getirmeye çalıştım. S3, Lambda, Bedrock ve DynamoDB kullanarak CV’leri otomatik işleyen ve değerlendiren uçtan uca bir akış kurmak mümkün oldu. Kritik nokta mimariden çok değerlendirme mantığıydı. Özellikle modelin gereğinden yüksek puan verme eğilimi ister istemez prompt tasarımını ve çıktı kontrolünü işin merkezine taşıdı. Genel olarak bu çalışma, hem Amazon Bedrock’u pratikte denemek hem de serverless servislerle hızlıca çalışan bir prototip çıkarmak açısından benim için faydalı bir deneyim oldu.
Proje kodlarına silverstone1903/serverless-ats üzerinden erişebilirsiniz.
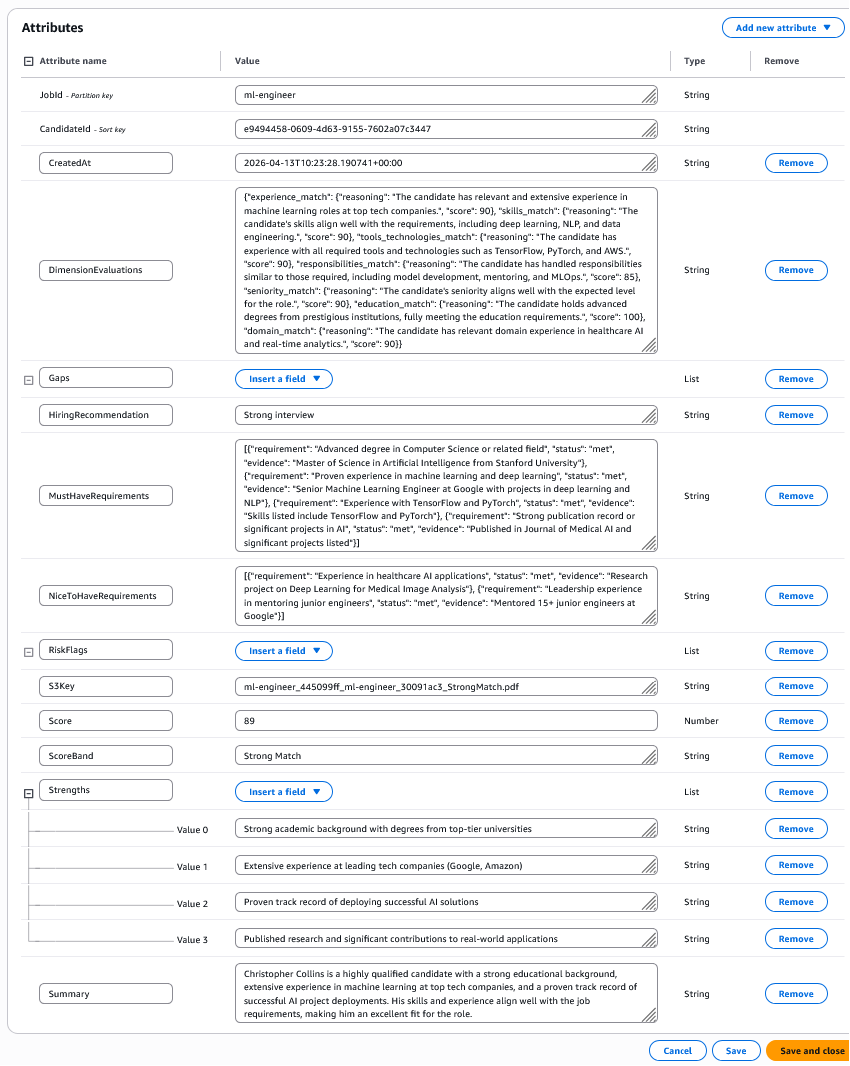
Arayüze ait ekran görüntüleri:
Aday değerlendirme sonucu ve DynamoDB'ye kaydı